1. Einführung
1Das Konzept der regulären Ausdrücke (abgekürzt "RA" oder "RE" für engl. Regular Expressions) ist ein System zur variablen bzw. vereinfachten Beschreibung von Zeichenketten ("strings"). Sie werden praktisch ausschließlich zum Auffinden von Zeichenketten in Textdokumenten verwendet. Als ihr "Erfinder" gilt der amerikanische Mathematiker Stephen Cole Kleene (1909-1994). Ursprünglich aus dem Bereich der Informatik bzw. der Programmierung stammend, sind die regulären Ausdrücke auch im Umfeld der Korpuslinguistik von großem Nutzen.
2Ein kleines Beispiel kann Funktionsweise und Vorteile ihres Einsatzes illustrieren. Angenommen, man möchte in einem Text die beiden Wörter "Band" und "Bund" finden. Ohne die Verwendung von regulären Ausdrücken müsste man, nach einander, zunächst nach dem Wort "Band" und anschließend nach dem Wort "Bund" suchen:
Finde "Band" in Text Finde "Bund" in Text
4Beim Einsatz regulärer Ausdrücke wäre diese Aufgabe mit einer einzigen Suchaktion zu erledigen, nämlich folgendermaßen:
Finde "B[au]nd" in Text
6Die eckigen Klammern bezeichnen eine sogenannte Zeichenklasse, die in der Weise zu interpretieren ist, dass innerhalb der Klammern aufgeführten Zeichen als Alternativen zu verstehen sind. Im gegebenen Beispiel wäre also paraphrasiert zu lesen: Find ein großes B, gefolgt von entweder einem a oder einem u, gefolgt von einem n, gefolgt von einem d.
7Das Konzept der Regulären Ausdrücke ist in einer Vielzahl von Softwareprodukten implementiert (u. a. in den meisten Editoren, außerdem auch im Datenbankmanagementsystem MySQL). Nicht selten gibt es dabei anwendungsspezifische Besonderheiten und Erweiterungen des Basiskonzepts der Regulären Ausdrücke.
2. Literale und Metazeichen
8Das Konzept der REs unterscheidet zwischen Literalen und Metazeichen. Literale stehen jeweils für sich selbst, Metazeichen haben Sonderbedeutung. Die wichtigsten Metazeichen lauten wie folgt:
| Metazeichen | Kategorie | Bedeutung |
| . (Punkt) | Platzhalter | ein beliebiges Zeichen |
| [a-z] | Zeichenklasse | Ein beliebiges Zeichen aus dem Bereich zwischen a und z. Grundlage ist die Anordnung der Zeichen in der ASCII-Tabelle. Zeichenbereiche bei denen der ASCII-Wert des erstgenannten Zeichens größer ist als der des folgenden, sind ungültig. Nicht ASCII-kodierte Buchstaben sind nicht enthalten (z. B. deutsche Umlaute oder ß) |
| [^0-9] | Zeichenklasse | Das ^ ("Dach") innerhalb einer Zeichenklassendefinition bezeichnet eine Negation. Hier im Beispiel: keine Ziffer |
| \d | Zeichenklasse | beliebige Ziffer (= [0-9]) |
| \s | Zeichenklasse | beliebiger Whitespace-Character (Leerzeichen oder Tabstopp; = [ \t]) |
| \w | Zeichenklasse | beliebiges alphanumerisches Zeichen (Buchstabe oder Zahl; keine Satzzeichen, Leerzeichen etc.; auch keine nicht-ASCII Sonderzeichen wie z. B. deutsche Umlaute oder ß) |
| \D | Zeichenklasse | Beliebiges Zeichen außer Ziffern. Generell steht die Großschreibung des entsprechendes Buchstabens jeweils für die Negation der mit dem Kleinbuchstaben markierten Zeichenklasse. |
| ^ | Kontextoperator | Das ^ *außerhalb* einer Zeichenklassendefinition bezeichnet den Anfang einer Zeile |
| $ | Kontextoperator | Ende eines Strings (Zeile, Feld ...) |
| \b | Kontextoperator | Wortgrenze |
| \A | Kontextoperator | Beginn des Textes |
| \z | Kontextoperator | Ende des Textes |
| * | Wiederholungsoperator | 0-n Wiederholungen des vorangegangenen Zeichens (greedy!) |
| + | Wiederholungsoperator | 1-n Wiederholungen des vorangegangenen Zeichens (greedy!) |
| ? | Wiederholungsoperator | 0 oder 1 Wiederholungen des vorangegangenen Zeichens |
| {n,m} | Wiederholungsoperator | mindestens n, maximal m Vorkommen (Beispiel: {1,3}) |
| {n,} | Wiederholungsoperator | mindestens n Vorkommen (Beispiel: {2,}) |
| {,m} | Wiederholungsoperator | maximal m Vorkommen (Beispiel: {,3}) |
| {n} | Wiederholungsoperator | exakt n Vorkommen (Beispiel: {2}) |
- 10
- Um Metazeichen in Literale zu verwandeln, müssen ihnen Backslashes vorangestellt werden (sog. Maskierung): Der RE \[Haus\] "matcht" den String "Haus" zwischen eckigen Klammern, also [Haus]. Ohne die Maskierung würde es sich um eine Zeichenklasse, bestehend aus den Zeichen "H", "a", "u" und "s" handeln.
11Beispiele
| Metazeichen | Bedeutung |
| [abcDE396;:] | Zeichengruppe (jeweils genau ein Zeichen aus der angegebenen Liste, also: entweder a oder b oder c oder D ...). |
| [a-zäöüß] | Ein beliebiger ASCII-kodierter Kleinbuchstabe inklusive der genannten deutschen Sonderzeichen |
| [^0-9] | keine Ziffer |
| [%-.] | Matcht alle Zeichen, deren ASCII-Werte zwischen x25 (%) und x2E (.) liegen, nämlich: %,&'()*+´-. (s. ASCII-Tabelle) |
| [^\t-~] | Alle *nicht*-ASCII-Zeichen |
3. Greediness
13Bei Wiederholungsoperatoren, die 0-n oder 1-n Wiederholungen beschreiben, spielt die "Greediness" ("Gierigkeit") eine Rolle.
14Beispiel: Man möchte in einem XML-Dokument die sog. Tags, also die mit < beginnenden und mit > endenden Strings "matchen" (= finden). In natürlicher Sprache würde man formulieren: "Finde einen String, der mit einem < beginnt, daran anschließend eine beliebige Anzahl von beliebigen Zeichen enthält und mit einem > abgeschlossen wird". In der formalen Sprache der regulären Ausdrücke würde man zunächst scheiben: <.*>. Durch die Greediness von * wird im folgenden Beispiel nicht die schließende spitze Klammer des ersten Tags (<h1>), sondern die des zweiten Tags (</h1>) gematcht:
Greediness von *. Die Farben von Regulärem Ausdruck und String korrespondieren. Regulärer Ausdruck: <.*> String: <h1>Einführung in die Regulären Ausdrücke</h1>
16Bei Verwendung eines nicht-"gierigen" Wiederholungsoperators wird hingegen die schließende spitze Klammer des ersten Tags gematcht. Leider enthält das Basiskonzept der Regulären Ausdrücke keinen nicht-gierigen Wiederholungsoperator. In manchen Implementierungen existieren solche Operatoren jedoch als spezifische Erweiterung. Vim z.B. kennt den nicht-gierigen Wiederholungsoperator \{-}:
Non-Greediness von \{-}. Die Farben von Regulärem Ausdruck und String korrespondieren.
Regulärer Ausdruck: <.\{-}> # Vim-Syntax
String: <h1>Einführung in die Regulären Ausdrücke</h1>18Möglichkeit, non-greediness mit greedy-Operatoren */+ durch Negation nachzubilden (am Beispiel html-Tags: "nicht '>' "):
<[^>]*>4. Alternativen
- 20
- Alternativen werden angeben durch "|" (sog. "pipe"):
| [aeiou]|[3-8] | Findet entweder einen Vokal oder eine Ziffer zwischen 3 und 8 |
| aber|und | entweder "aber" oder "und" |
5. Gruppierung und Backreferencing
- 22
- Die Definition einer Gruppierung erfolgt durch runde Klammern.
23Suche nach "der" oder "die" oder "das":
(der)|(die)|(das) (| gibt Alternativen an)
- 25
- Eine Gruppe kann durch \1 (in manchen Implementierungen auch $1) angesprochen werden (sog. Backreferencing). Bei mehreren Gruppen, orientiert sich die Nummerierung an der Reihenfolge deren Definition von links nach rechts. Beispiele:
| ([A-Za-z])\1 | Doppelungen ("Geminate") von beliebigen Buchstaben im ASCII-Bereich |
| (A)(B)\2\1 | Zeichenfolge ABBA |
6. REs in verschiedenen Programmen
6.1. vim/gvim
6.1.1. vim-spezifische Operatoren bzw. Besonderheiten
| Metazeichen | VIM-Besonderheit | Kategorie | Bedeutung |
| \_. | Platzhalter | beliebiges Zeichen, inklusive Zeilenende | |
| \_s | Zeichenklasse | Leerzeichen oder Tabulator oder Newline | |
| \< | Kontextoperator | Anfang eines Wortes | |
| \> | Kontextoperator | Ende eines Wortes | |
| + | \+ | Wiederholungsoperator | 1-n Wiederholungen des vorangegangenen Zeichens (greedy!) |
| \{-} | Wiederholungsoperator | 0-n Wiederholungen des vorangegangenen Zeichens (non-greedy) | |
| ? | \= | Wiederholungsoperator | 0 oder 1 Wiederholungen des vorangegangenen Zeichens |
| {n,m} | \{n,m} | Wiederholungsoperator | mindestens n, maximal m Vorkommen (Beispiel: {1,3}) |
| {n,} | \{n,} | Wiederholungsoperator | mindestens n Vorkommen (Beispiel: {2,}) |
| {,m} | \{,m} | Wiederholungsoperator | maximal m Vorkommen (Beispiel: {,3}) |
| {n} | \{n} | Wiederholungsoperator | exakt n Vorkommen (Beispiel: {2}) |
| (ab) | \(ab\) | Gruppierung |
6.1.2. Beispiele
| [ \n]\+ein[\n ]\+ | "ein" am Anfang, Ende oder in der Zeile |
| \<ein\> | "ein" am Anfang, Ende oder in der Zeile (\< und \> markieren Wortgrenze) |
| ^$ | Leere Zeilen |
| ^$\n | Leere Zeilen inklusive newline (wichtig bei Tilgung leerer Zeilen durch Ersetzung:) |
| ^[ \t]*$ oder ^\s*$ | Leere Zeilen mit Whitespace-Characters (Leerzeichen und Tabulatoren) |
| \([a-zA-Z]\)\1 | Buchstabenwiederholungen (mm, nn, ...); runde Klammern der Gruppendefinition müssen maskiert werden. |
| [ \n]\([^ ]\+\)\_s\+\1 | Wortwiederholungen (die die) |
| \(.\+\)[\_s\n]\+\1 | Wiederholung von Wortgruppen |
| <\_.\{-}> | XML-Tags (zeilenübergreifend); \_. = "any character including newline"; \{- = non-greedy operator |
| [A-ZÄÖÜa-zäöü]{1,3}[ -]+[A-Za-z]{1,2} +[1-9][0-9]*[HE]? | Deutsche Kfz-Kennzeichen (Möglichkeit 1) |
| [A-ZÄÖÜ][A-ZÄÖÜ]*[A-ZÄÖÜ]*-[A-ZÄÖÜ][A-ZÄÖÜ]* [1-9][0-9]*[0-9]*[0-9]*[EH]* | Deutsche Kfz-Kennzeichen (Möglichkeit 2) |
| \([A-Za-z]\)\1 | Doppelungen ("Geminate") von beliebigen Buchstaben im ASCII-Bereich |
| \(A\)\(B\)\2\1 | Zeichenfolge ABBA |
29Ersetzungen:
| :%s/\([.,!?;"«»]\)/ \1 /g | Abtrennung von Satz- und Anführungszeichen durch Leerzeichen |
| :%s/^\s*$\n//g | Löschen leerer Zeilen (auch mit Whitespace-Characters; wichtig: \n) |
| :%s/\s\+/\r/g | Ersetzung von Whitespace-Characters durch Zeilenumbrüche (= Erzeugung einer Tokenliste) |
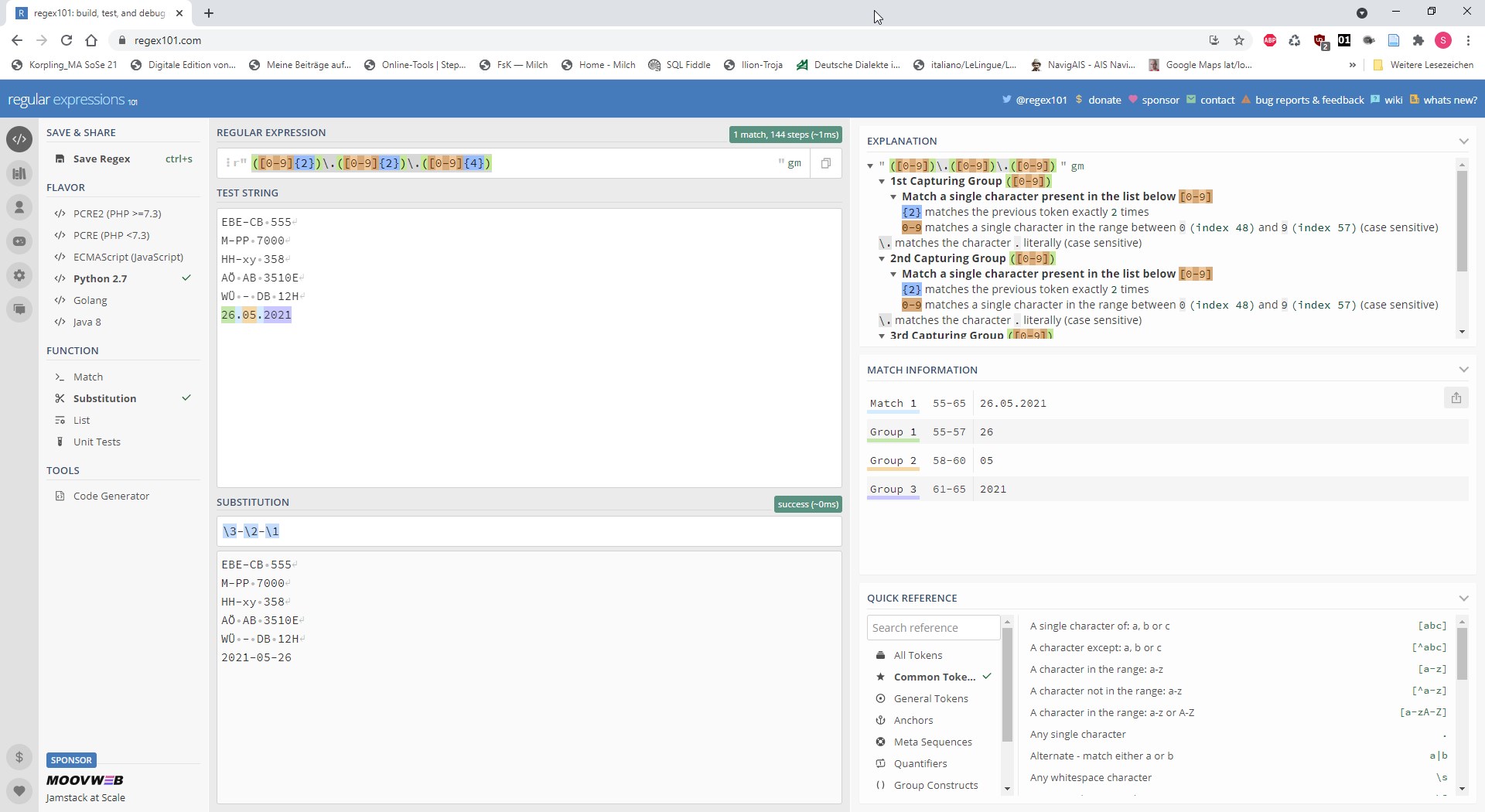
| :%s/\(\d\d\)\.\(\d\d\)\.\(\d\d\d\d\)/\3-\2-\1/g | Umwandlung von Datumsformaten nach dem Muster: 02.09.2020 -> 2020-09-02 (Möglichkeit 1) |
| :%s/\([0-3]?[0-9]\)\.\([01]?[0-9]\)\.\([0-9]{2,4}\)/\3-\2-\1, \2.\1.\3/g | Umwandlung von Datumsformaten nach dem Muster: 02.09.2020 -> 2020-09-02 (Möglichkeit 2; mit Mehrfachersetzung) |
6.1.3. Lookaround
31Das Konstrukt "Lookaround" erlaubt die Prüfung der Umgebung, in der sich ein Zeichenmuster befindet, ohne dass die Umgebung Teil des Suchmusters ist. Lookaround unterscheidet zwischen Lookahaed und Lookbehind.
32Vim-Syntax:
| Funktion | Operator |
| positive lookahaed | \@= |
| positive lookbehind | @<= |
| negative lookahaed | \@! |
| negative lookbehind | \@<! |
34Die Operatoren werden hinter ein Zeichenmuster geschrieben, das durch runde Klammerung als Gruppe definiert wurde.
35Beispiele:
| regex (vim-Syntax) | Beschreibung | Beispiele |
| a\(me\)\@= | "a" gefolgt von Zeichenfolge "me" (positive lookahead) | Damen, Kameraden |
| \(D\)\@<!a | "a" nicht auf "D" folgend (negative lookbehind) | faul, dagegen; nicht: Damen |
37Im Unterschied zum letzten Beispiel ist das Zeichen vor dem a bei Verwendung einer negierten Zeichenklasse Teil des "gematchten" Musters:
| [^D]a | Kein D vor a | faul, dagegen |
- 39
- Vim kann bei Suchen Groß- und Kleinschreibung berücksichtigen (:se noignorecase) oder auch nicht (:se ignorecase). Die entsprechende Einstellung beeinflusst auch die Suche nach regulären Ausdrücken. Bei Einstellung :se ignorecase "matcht" der RE "Haus" auch den String "HAUS".
- Kommando :nohl ("no highlighting" -> entfernt farbige Hervorhebung der gefundenen Muster)
6.2. sed
40sed steht im Terminal aller Linux-Umgebungen zur Verfügung (auch im Virtuellen Desktop des DHVLab). Aufruf: sed 'Kommando(s)' Dateiname(n)
41Die folgenden Ersetzungskommandos sollten vor der Tokenisierung von Textmaterial im Virtuellen Desktop des DVHLab in allen zu importierenden Dateien durchgeführt werden:
s/\xef\xbb\xbf//g # Löschung des Byte Order Marks (BOM) für UTF-8 s/\x0d//g # Entfernung von Windows-Zeilenumbrüchen # Abkürzungspunkte: s/z.B./z<#p>B<#p>/g s/ca./ca<#p>/g s/Dr./Dr<#p>/g s/“/"/g # typographische Anführungszeichen -> x0022 s/„/"/g # typographische Anführungszeichen -> x0022 s/’/'/g # typographisches Anführungszeichen -> x0027 s/,,/"/g # typischer OCR-Fehler s/ / /g # Ersetzung von no-break-space (x00a0) durch "normales" Leerzeichen s/\.\([^ ]\)/'\1/g s/([.!?;:"\'])/ \1 /gc # Isolierung von Satzzeichen durch voran- und nachgestelltes Blank s/[ ]+/ /gc # Ersetzung von mehr als einem auf einander folgenden Blanks durch genau ein Blank # "Rückersetzung" der Abkürzungspunkte s/<#p>/./g
43Auf der Kommandozeile ist die sequentielle Kombination mehrerer sed-Kommandos durch eingefügte Strichpunkte möglich:
s/\xef\xbb\xbf//g; s/([.!?;:"\'])/ \1 /gc; s/[ ]+/ /gc
6.3. MySQL/MariaDB
45Operatoren: rlike, regex (beide funktionsidentisch)
46Speziell ältere Versionen von MySQL oder MariaDB sind nicht multibyte-safe. Nachfolgende Abfrage liefert auf unterschiedlichen DBMS-Versionen unterschiedliche Ergebnisse. "1" steht für "Match" (Treffer), "0" für keinen Match.
471) Server-Version: 10.6.16-MariaDB-0ubuntu0.22.04.1 - Ubuntu 22.04 (https://dhvlab.gwi.uni-muenchen.de/sql/index.php):
SELECT 'Ä' RLIKE '[Öä]' COLLATE utf8mb4_bin; -> 0
492) Server-Version: 5.7.43-47-57-log - Percona XtraDB Cluster (GPL), Release rel47, Revision 69b5c96, WSREP version 31.65, wsrep_31.65 (https://pma.gwi.uni-muenchen.de/index.php?route=/&server=1):
SELECT 'Ä' RLIKE '[Öä]' COLLATE utf8mb4_bin; -> 1 SELECT 'Ü' RLIKE '[Öä]' COLLATE utf8mb4_bin; -> 1
512) matcht im String "[Öä]" sowohl ein Ä als auch ein Ü. Dies liegt an der UTF-8-Kodierung der Zeichen:
Ö -> 11000011 10010110 ä -> 11000011 10100100 Ä -> 11000011 10000100 Ü -> 11000011 10111100
53Der UTF8-Code jeder der vier Buchstaben enthält ein identisches erstes Byte. Dies führt zum "Match", da die Regex-"Engine" von MySQL 5.7.43 jeweils nur einzelne Bytes miteinander vergleicht und nicht "weiß", dass bestimmte Zeichen mit mehr als einem Byte kodiert sein können.
7. Übungstexte
54Quelle: https://www.projekt-gutenberg.org/eichndrf/taugen1/taugncht.html (2022-07-06)
8. Nützliche Links
- 56
- Einführung in die RAs von Stefanie Schneider (MAX)
- https://regex101.com (Test für reguläre Ausdrücke)
{kind=link}
- 58
- http://vimdoc.sourceforge.net/htmldoc/pattern.html (detaillierte VIM-Dokumentation)
- http://www.softpanorama.org/Editors/Vimorama/vim_regular_expressions.shtml (Besonderheiten der REs in vim; Seite bitte nur mit Addblocker aufrufen!)
- Sammlung verschiedener REs in vim-Syntax: http://vim.wikia.com/wiki/Search_patterns
- Reguläre Ausdrücke (RAs) in MySQL (ITG/slu) (Besonderheiten im Umgang mit REs in MySQL)