
1. Lexikographie - zur diffusen Situation einer wichtigen Subdisziplin
1Die Entstehungsgeschichte der sachorientierten Enzyklopädie vollzog sich in - mitunter nicht sehr klarer - Abgrenzung von der bereits früher etablierten Gattung der Wörterbücher; letztlich wurde die einzelsprachunabhängige Verknüpfung reiner Sachinformationen erst mit dem Aufbau von Wissendatenbanken oder Ontologien möglich.
2Die Gattung des Wörterbuchs1 ist ein Produkt der ersten medialen Revolution, nämlich der Durchsetzung des Buchdrucks, und insofern geradezu emblematisch für die sogenannte Gutenberg-Galaxis (vgl. McLuhan 1962a): In den europäischen Sprachgemeinschaften entfaltete sich die Lexikographie im Laufe des 16. Jahrhunderts schnell. Es entwickelte sich mit den ersten großen Referenzwörterbüchern, vor allem im Gefolge des Vocabolario degli Accademici della Crusca (1612), eine kanonische Form, die mit großer Selbstverständlichkeit grosso modo bis in die jüngste Zeit, ja bis in die Gegenwart reproduziert wird. Wörterbücher haben in erheblichem Maße zur Herausbildung von Standardvarietäten beigetragen; nicht selten wurden sie ganz bewusst als Instrument der Standardisierung geplant und eingesetzt. Aber komplementär und nicht selten in direkter Verbindung entstand auch eine durchaus ambitionierte und elaborierte Dialektlexikographie; so wurde im Italien des 19. Jahrhunderts eine ganze Serie bis heute wichtiger Dialektwörterbücher verfasst (vgl. Boerio 1829, Cherubini 1814, di Sant'Albino 1859, u.a.), die im Selbstverständnis ihrer Autoren zur Kenntnis und Verbreitung des Standards beitragen sollten, de facto jedoch gerade die Dialekte systematisch dokumentierten. In jedem Fall ist die europäische Lexikographie ein wichtiger und unverzichtbarer Pfeiler des kulturellen Gedächtnisses; die Thesaurierung des Wortschatzes als solche ist gewissermaßen materialisierte historische Erinnerungsarbeit.
3Mittlerweile, vor allem im Gefolge der zweiten medialen Revolution, hat sich allerdings die Lexikographie sehr stark verändert; diese wichtige Subdisziplin gehört wahrscheinlich zu den Kernbereichen der Geisteswissenschaften, die sich sehr früh und in tiefgreifenden Weise die Optionen der neuen Medien zu eigen gemacht haben. Auch wenn sie meist nicht explizit dazu gerechnet wird, gehört die Lexikographie zum selbstverständlichen Fundament der Digital Humanities. Sie ist im Übrigen für den inneren Zusammenhang der humanities und der so genannten Philologien von besonderer, integrativer Bedeutung, da sie von allen Teildisziplinen (Literatur-, Sprach-, Kultur- und Geschichtswissenschaften) gleichermaßen gebraucht werden. Die aktuelle Lage ist unübersichtlich; sie steht offenkundig im Zeichen des Übergangs und ist dementsprechend disparat: Nebeneinander stehen Werke, die sehr unterschiedlichen Digitalisierungsgraden im Sinne von Lücke 2019 entsprechen:
| Mediale lexikographische Formate | Digital.grad | |
| (a) | Printwörterbücher, die nicht abgeschlossen sein müssen (z.B. VS) | 0 |
| (b) | retrodigitalisierte, aber nicht/kaum tiefenerschlossene Printwörterbücher, die im Internet wie ein paginiertes Buch gelesen bzw. konsultiert werden können (z.B. FEW en ligne, REW), deren Inhalt jedoch nicht elektronisch durchsuchbar ist; Bilddateien oder auch nicht mit elektronischem Text hinterlegte PDFs (z. B. die in archive.org abrufbare Version des REW) | 1 |
| (c) | Wörterbücher auf der Basis von digitaler Textverarbeitung aber ohne Webtechnologie, deren Text elektronisch durchsuchbar, jedoch nicht logisch strukturiert oder bestenfalls teilstrukturiert ist (z.B. Foti 2015) | 2 |
| (d) | genuin virtuelle Wörterbücher, deren Inhalt als vollstrukturierter elektronischer Text in mehr oder minder feiner Granulierung vorliegt und deren Publikation von vorneherein mit Webtechnologie konzipiert und realisiert wurde (z.B. LEO, TLIO) oder retrodigitalisierte und tiefenerschlossene Printwörterbücher, die nicht abgeschlossen sein müssen, aber deren Inhalt sekundär feingranuliert strukturiert und webtechnologisch aufbereitet wurde und jetzt mit Suchfiltern im Web angeboten wird (z.B. AWB) | 3 |
4Zur Disparität der Gegenwartslexikographie trägt aber auch die Tatsache bei, dass sich gerade mit dem technologisch avanciertesten Digitalisierungsgrad 3 eine lexikographische Ausrichtung Bahn gebrochen hat, die sich von der Tradition sehr stark unterscheidet; exemplarisch ist hier der Dienst LEO zu nennen: LEO zeichnet sich einerseits durch seine Dynamik in Bezug auf die erfassten Lemmata und den äußerst reichhaltigen und dynamischen Bestand an Beispielen aus und kann schnell auf Neologismen und Frequenzverschiebungen regieren; aber andererseits verzichet LEO auf viele metalexikalische Informationen (Erstbeleg, Herkunft, Registerzuweisungen usw.). Immerhin werden die Wortarten spezifiziert, morphologische Eigenschaften genannt (z.B. Pluraformen) und Varianten, etwa schweizerisches oder österreichisches Standarddeutsch aufgeführt; sehr detailliert wird auf Fachsprachen eingegangen (vgl. ita. corona). Außerdem wird das jeweilige Stichwort, oder: Lemma, in zahlreichen Kontexten (Kollokationen und Phraseologismen) dokumentiert; vgl. den kleinen Ausschnitt aus dem Artikel cellulare:
| il cellulare [TELEKOM.] - telefono | das Handy Pl.: die Handys [ugs.] |
| il cellulare - della polizia | der Polizeibus |
| il cellulare - della polizia | der Polizeiwagen Pl.: die Polizeiwagen |
| il cellulare [TELEKOM.] - telefono | das Mobiltelefon Pl.: die Mobiltelefone |
| il cellulare [TELEKOM.] | das Natel Pl.: die Natels (Schweiz) |
| (Quelle) |
5LEO ist nicht kollaborativ, bietet seinen Nutzern jedoch ein Diskussionsform (vgl. die Diskussion zu fidanzato). Gerade die genuin webbasierte Lexikographie polarisiert daher - zu Unrecht - die Nutzer; es handelt sich ja nicht um ein Angebot mit substituierendem, sondern mit komplementärem Inhalt. Massiv verdrängt und mittelfristig substituiert wird jedoch das Trägermedium des Drucks und das korrespondierende Format der Seite.
1.1. Das Stiefkind der Wikimedia: der Wikizionario
6Wie wenig das gewaltige Potential der neuen Medien bislang ausgeschöpft wird - und wie stark auch webbasierte Lexikographie (vielleicht unbewusst) der papierenen Konzeption verpflichtet bleibt - zeigt sich ausgerechnet im entsprechenden Projekt der Wikimedia, das ita. Wikizionario, engl. und deu. Wiktionary heißt. Die ita. Version ist keineswegs klein; am Tage der Konsultation hieß es:
7"Oggi è lunedì 4 maggio 2020 e al momento abbiamo 512 320 lemmi e 76 035 utenti." (Quelle)
8Diese Zahl enthält allerdings auch die Artikel, in denen ital. Wörter Übersetzungsäquivalente anderer Sprachen sind. Die konzeptionellen Defizite sollen ausgehend von dem beliebig gewählten Beispiellemma ita. chat ‘Chat’ skizziert werden.
1.1.1. Defizit: stringbasierte Verknüpfung der Lemmata
9Das ita. Lemma ist mit 77 anderen einzelsprachigen Versionen des Projekts verbunden:
Quelle Wikizionario
10Aber die Verknüpfung erfolgt offenkundig nur über den Signifikanten, d.h. über die Kette der Buchstaben, den String, c + h + a + t, denn die Verknüpfung erfasst auch fra. chat, das jedoch 'Katze' (ita. gatto) bedeutet. Wieso manche der verknüpften Lemmata anderer Sprachen auf der Hauptseite des ita. Artikels erscheinen (und nicht nur in der linken Randspalte, wie z.B. in der deu. Version) ist unklar. Die einzelsprachlichen Bezeichnungen sind also nicht mit den durch Wikidata bereitgestellten Q-IDs verbunden (CHAT , KATZE ). Dadurch würden semantisch abwegige Homographe, wie fra. chat ‘Katze’, blockiert:
| engl. chat | Q146 |
| deu. Chat | |
| ita. chat | |
| Synonyme aus 51 anderen Sprachen | |
| fra. chat ‘Katze’ | Q287198 |
| Synonyme aus 235 anderen Sprachen |
11Da also in Wikidata ohnehin jede Q-ID mit der Liste sämtlicher korrespondierender Wikedia-Artikel verbunden ist, hätte es doch nahe gelegen aus den semantisch bereits eindeutig verknüpften Lemmata der Wikipedia-Enzyklopädie parallel das Gerüst des Wörterbuchs zu extrahieren und kollaborativ durch die Nutzer anreichern zu lassen. Vgl. den folgenden Screenshot:
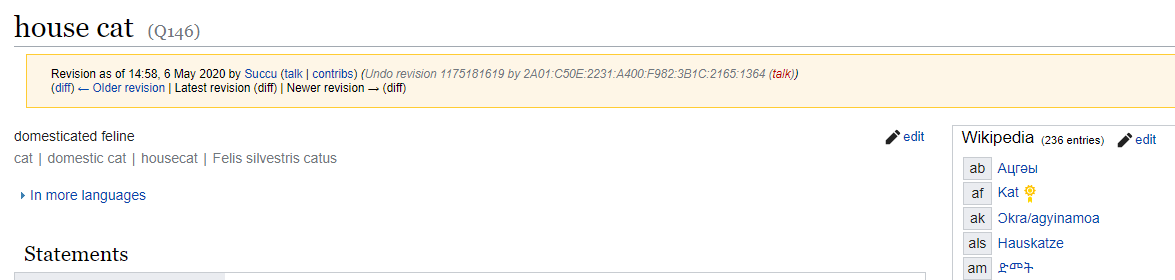
Quelle Wikidata
1.1.2. Defizit: keine konsequente Vergabe von Lemma-IDs
12Mit der fehlenden Integration und Verflechtung der unterschiedlichen Wikimedia-Projekte untereinander hängt ein weiteres, gravierendes Defizit von Wiktionary zusammen; analog zu den sachbezogenen Q-IDs sollten in Wikidata auch persistente Identifikatoren für einzelsprachliche Bezeichnungen (Wörter) vergeben werden; die Umsetzung dieses strukturell wichtigen Vorhabens scheint aber ins Stocken geraten zu sein; auf der Seite findet sich eine Liste von 10.000 Lemmata sowie der Hinweis:
"This page was last edited on 15 August 2018, at 16:15." (Quelle)
Es erhebt sich also die Frage, warum die Wiktionary-Einträge, wenn sie schon unabhängig von Wikidata aufgebaut werden, nicht zumindest eingesetzt werden, um den reichlich schmalen Bestand von L-IDs zu erweitern.
2. Konzept-und Bezeichnungsrelationen2
13Unabhängig von den Wikimedia-Projekten sollten lexikographische Online-Angebote grundsätzlich jedes Lemma mit einem persistenten Identifikator versehen; am besten wäre es natürlich bereits existierende IDs zu übernehmen, so wie sie von manchen Wörterbüchern bereits geliefert werden; etwa im Georges 1913 [1998] ist jeder Eintrag mit einem Permalink auf der Basis eines identifikators verbunden (etwa im Fall von lat. terra sind es die Ziffern der folgenden URL: http://www.zeno.org/nid/20002688484). In Verbindung mit dem bereits sehr gut ausgebauten Bestand an sachbezogenen IDs aus dem Wikidata-Projekt ließen sich so systematische und formalisierbare Relationen formulieren und verschränken. Im Entwurf des lexikographischen Projekts LexiCon sind drei verschiedene Beziehungstypen vorgesehen:
- Beziehungen zwischen Bezeichnungen und Konzepten
- Beziehungen zwischen Konzepten; sie bestehen bereits in Gestalt der Item-Property-Value-Tripel oder vergleichbarer RDF-Tripel.
- Beziehungen zwischen Bezeichnungen, die ebenfalls als Tripel kodiert werden könnten; insbesondere zwei Relationen sind aus historisch-lexikologischer Sicht grundlegend, um die Herkunft einer Form zu beschreiben, nämlich Vorläufer und Entlehnungen:
| elementare sprachhistorische Relationen | ||||
| Item | Property | Value | ||
| (1) | ita. città | Vorläufer | lat. civitatem | Etymon |
| (2) | ita. chat | Entlehnung | engl. chat | |
14Schematisch ergibt sich damit das folgende Beziehungsgefüge:
| ↓ ontolog. Relationen ↑ |
KONZEPT 1 | → | Bezeichnung 1 | ↓ sprachgesch. Relationen ↑ |
| (evtll. → | Bezeichnung 2, 3 usw.) | |||
| KONZEPT n | ← | Bezeichnung n | ||
| (KONZEPT o, p usw. | ← evtll.) |
15Auf der Nutzeroberfläche ergeben sich daraus zwei Zugriffsrichtungen, vom KONZEPT zur Bezeichnung und umgekehrt.
3. Ein mögliches Szenario mit lateinisch ~ italienischem Kern
16Die Plattform LexiCon könnte ausgehend von den Romanischen Sprachen mit einem besonderen Fokus auf dem Italienischen entwickelt werden. Der Kern liefert der Wortbestand des REW, wo romanische Entwicklungen mit ihren meist lateinischen Etyma verknüpft sind. Dieses Standardwerk der Romanistik lemmatisiert nach (ganz überwiegend lateinischen) Etyma, denen jeweils die Entsprechungen der romanischen Standardsprachen sowie im Rahmen der damaligen Verfügbarkeit mehr oder weniger zahlreiche dialektale Kognaten zugeordnet werden; das Wörterbuch wird derzeit im Rahmen einer linguistischen Dissertation (von Florian Zacherl) in ein strukturiertes und tiefenerschlossenes lexikographisches Korpus überführt; dabei erhält jede im Artikel erfasste Bezeichnung eine ID. Zwischen den per ID erfassten Belegen des REW bestehen genau die drei oben herausgestellten lexikographischen Relationen (I - III); sie können durch Verknüpfung mit verfügbaren anderen IDs desselben Worts inhaltlich in einem offenen System auch über das Romanische hinaus quasi unbegrenzt erweitert und inhaltlich präzisiert werden, wie die folgende, ganz unvollständige Auswahl am Beispiel von REW 4833, lactūca, andeutet:
| lat. lactūca → ID Georges | ||
| engl. lettuce ?→ ID OEtD, ID_LEO |  [...] lat. lactūca REW; ID lat. Bez. = 4833 [...] lat. lactūca REW; ID lat. Bez. = 4833 |
ahd. lat(t)uh(ha), lat(t)ih(ha) → ID AWD |
| ita. lattuga → ID LEO ID TLIO |
fra. laitue → ID LEO, ID TLFI |
rum. laptucă → ID DEX online |
| Vorläufer: grün ~ gelb | Entlehnung: grün ~ rosa3 | ||
17Die zwei elementaren Relationen sowie die Verwandtschaftsbeziehungen können weitgehend aus der Anlage des (REW) extrahiert und Paaren von Bezeichnungen zugeordnet werden. Zwischen dem nummerierten Stichwort des REW-Artikels (hier: 4833 lactūca) und den im Artikel genannten Bezeichnungen besteht grundsätzlich die Relation ‘Etymon’; da die zugehörige Sprache jeder Bezeichnung explizit genannt wird (gelegentlich in Gestalt eines Orts), können die romanischen Bezeichnungen automatisch von nicht-romanischen Bezeichnungen getrennt werden; zwischen lat. Stichwörtern (die natürlich immer auch Bezeichnungen sind) und romanischen Bezeichnungen ergibt sich die Relation ‘Vorläufer’. In allen anderen Fällen, d.h. zwischen nicht-romanischen Stichwörtern und romanischen Bezeichnungen im Verlauf des Artikels oder zwischen lat. Stichwörtern und nicht-romanischen Bezeichnungen, die in den Artikeln auch immer wieder genannt werden (wenngleich nicht im zitierten Beispiel) liegt dagegen die Relation ‘Entlehnung’ vor. (Zudem wird die Entlehnung aus einer romanischen in eine andere romanische Sprache in dieser Quelle systematisch durch den Pfeil > markiert; dieser Fall ist im zitierten Beispiel ebenfalls nicht belegt). Das REW kann deshalb als start up eingesetzt werden und bei der Integration der synchronen und diachronen Perspektive eine wichtige Scharnierfunktion übernehmen. Diese Basis ließen sich dann durch weitere, nicht zuletzt dialektale Wörterbücher erweitern.
18Auf der sachbezogenen Ebene sind den Wörtern sodann die Wikidata-Q-IDs zu hinterlegen. Abhängig vom Wissensbereich stehen auf diese Weise mitunter recht umfangreiche, streng konventionalisierte taxonomische Hierarchien zur Verfügung, wie sich gerade am Beispiel von deu. Lattich (< lat. lactūca) gut zeigen lässt:
| referenziertes KONZEPT (Wikidata QID) | Taxonomischer Status (=) und hierarchische Relationen (⊂, ⊃) | verknüpftes KONZEPT ; Wikidata QID |
| (i) Gruppe (Klade) ⊃ (i)-(vi) | ASTERIDEN/EUASTERIDEN II; Q747502 | |
| (ii) Ordnung ⊂ (i) | ASTERNARTIGE ; Q21730 | |
| (iii) Familie ⊂ (ii) | KORBBLÜTLER ; Q25400 | |
| (iv) Unterfamilie⊂ (iii) |
CICHORIOIDEAE ; Q133142 |
|
| LATTICH, (Linné: LACTUCA ; Q578052) | = (v) Gattung ⊂ (iv), ⊃ (vi) | |
| (vi) Arten (...) | nn ; Q... |
19Auch die Implementierung von KONZEPT-Bezeichnungs-Relationen ist nicht ganz neu, denn sie werden bereits durch Online-Anwendungen unterstützt, z.B. durch den von WordNet (vgl. Fellbaum 2010) inspirierten, umfassenden und vielsprachigen Online-Thesaurus BabelNet (vgl.Navigli).
Bibliographie
- AWB = Frings, Theodor (1952-2015 ff.): Althochdeutsches Wörterbuch. Auf Grund der von Elias v. Steinmeyer hinterlassenen Sammlungen, Leipzig, Sächsische Akademie der Wissenschaften (Link).
- Boerio 1829 = Boerio, Giuseppe (1829): Dizionario del dialetto veneziano, Venezia (Link).
- Cherubini 1814 = Cherubini, Francesco (1814): Vocabolario milanese-italiano, 2 voll., Milano, Milano, Stamperia reale (Link).
- Crusca 1612 = Crusca (1612): Vocabolario degli Accademici della Crusca (Link).
- di Sant'Albino 1859 = di Sant'Albino, Vittorio (1859): Gran dizionario piemontese, Torino, UTET (Link).
- Fellbaum 2010 = Fellbaum, Christiane (Hrsg.) (2010): WordNet: An Electronic Lexical Database, Princeton, Princeton University (Link).
- FEW en ligne = atilf: Französisches etymologisches Wörterbuch (Link).
- Foti 2015 = Foti, Giuseppe (2015): Vocabolario del dialetto galloitalico di San Fratello, in: ArchivIA - Archivio istituzionale dell'Università di Catania, Tesi di dottorato, Area 10 - Scienze dell'antichità, filologico-letterarie e storico artistiche, Catania, Università di Catania (Link).
- Georges 1913 [1998] = Georges, Karl Ernst (1913 [1998]): Ausführliches lateinisch-deutsches Handwörterbuch, Hannover (Darmstadt) (Link).
- Krefeld u.a. 2020 = Krefeld, Thomas / Kümmet, Sonja / Lücke, Stephan / Berg-Weiß, Alexander (2020): Lexicographia Coniuncta (LexiCon): Aufbau einer webbasierten und bibliotheksgestützten lexikographischen Umgebung, in: Korpus im Text, Serie A, vol. 40112, München, LMU (Link).
- LEO = LEOs Wörterbücher (Link).
- Lücke 2019 = Lücke, Stephan (2019): Digitalisierung, in: Methodologie, VerbaAlpina-de 19/1 (Link).
- McLuhan 1962a = McLuhan, Marshall (1962): The Gutenberg Galaxy, London.
- Navigli = Navigli, Roberto (Hrsg.): BabelNet (Link).
- REW = Meyer-Lübke, Wilhelm (1935): Romanisches etymologisches Wörterbuch 3., vollst. neubearb. Aufl., Heidelberg, Winter (Link).
- TLIO = Leonardi, Lino (2017): Tesoro della Lingua Italiana delle Origini Il primo dizionario storico dell'italiano antico che nasce direttamente in rete fondato da Pietro G. Beltrami. Data di prima pubblicazione: 15.10.1997 (Link).
- VS = Piccitto, Giorgio / Tropea, Giovanni / Trovato, Salvatore C. (1977-2002): Vocabolario siciliano, vol. 5, Palermo, Centro di studi filologici e linguistici siciliani.