1. Einleitung
In SQL ist es anders als in Programmen wie Microsoft Word, dass man etwas immer rückgängig bearbeiten kann. Wenn man z.B. eine Zeile versehentlich in SQL gelöscht hat, verliert man einfach die Daten in der Zeile und kann sie nicht mehr zurückfinden. Deshalb wird in der folgenden Arbeit ganz am Anfang das Exportieren von Datenbank und Tabelle vorgestellt, mit dem man rechtzeitig Sicherheitskopien erstellen kann. Anschließend werden die sog. "Column Attributes" erklärt, die die Struktur einer Tabelle zeigen. Danach werden das "insert statement", "update statement", "delete statement" und "create/alter table " in SQL mit Beispielen erläutert, die alle in unserer eigenen Datenbank namens "labuser_" durchgeführt werden sollen (weil wir in unserer Kurs-Datenbank "lab_korplingma" kein Recht für Datenmanipulation haben). Zum Schluss wird "Index" in Tabelle vorgestellt.
2. Exportieren
2.1. Exportieren einer ganzen Datenbank/Tabelle
Beim Exportieren benutzen wir in der Regel die Exportmethode "Schnell - nur notwendige Optionen anzeigen". Wenn wir die Methode "Angepasst - zeige alle möglichen Optionen an" wählen, werden z.B. formatspezifische Optionen, Objekterstellungsoptionen, Datenerstellungsoptionen etc. zur Verfügung gestellt.
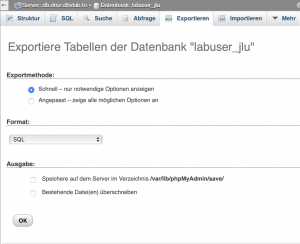
Exportieren einer Datenbank (am Beispiel von "labuser_jlu")
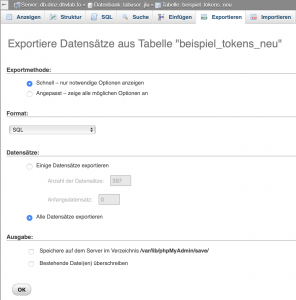
Exportieren einer Tabelle (am Beispiel von Tabelle "beispiel_tokens_neu")
2.2. Formate
Beim Exportieren gibt es verschiedene Formate wie SQL, CSV, Microsoft Word 2000 usw. Meistens werden die Formate SQL und CSV benutzt.
Mit dem Format CSV kann man die exportierte Tabelle durch z.B. Vim weiter bearbeiten:
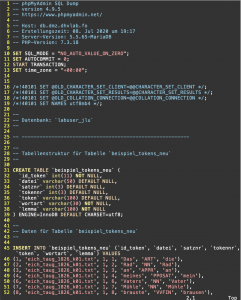
Exportieren einer Tabelle mit dem Format SQL (am Beispiel von Tabelle "beispiel_tokens_neu")
Die exportierte Tabelle mit dem Format CSV sieht wie eine "normale" Tabelle aus:
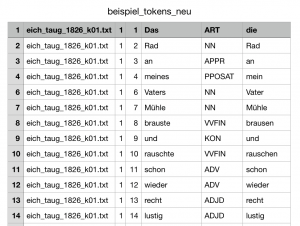
Exportieren einer Tabelle (Ausschnitt) mit dem Format CSV (am Beispiel von Tabelle "beispiel_tokens_neu")
3. Column Attributes
Bevor wir eine oder mehrere Zeilen in eine Tabelle einfügen, müssen wir die Struktur dieser Tabelle kennen, d.h. an welcher Stelle sollen wir welchen Typ von Daten einsetzen.
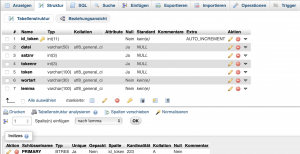
Struktur einer Tabelle (am Beispiel von Tabelle beispiel_tokens_neu)
Oder: DESC tabelle_name
Erklärung:
• Die erste Spalte zeigt alle sieben Spalten in der Tabellen „beispiel_tokens_neu“.
• Die zweite Spalte zeigt den Datentyp der jeweiligen Spalte in dieser Tabelle:
int(11): „integer value“, keine Dezimale. „11“ bedeutet, dass man maximal 11 Ziffern eingeben darf.
varchar(50): „varchar“ steht für „variable character“. “50” bedeutet, dass der Wert an dieser Stelle maximal 50 Charakters/Zeichen haben darf, sonst werden die überschüssigen Charakters bei der Speicherung einfach weggelassen. Im Vergleich zu CHAR kann man durch VARCHAR mehr Platz sparen beim Speichern: z.B. wenn man den Wert mit nur 5 Zeichen speichert, werden die überschüssigen 45 Zeichenplätze in varchar(50) einfach leer gelassen, während sie in char(50) gespeichert werden.
• Die „NULL“-Spalte bezeichnet, ob eine Spalte keinen Wert beinhalten darf.
• Die „Standard“-Spalte zeigt, wenn eine Spalte keinen Wert hat, was MySQL automatisch anzeigen wird.
• Der golden Schlüssel steht für „primary key“. Alle Werte in dieser Spalte sind natürlich einzig/“unique“.
• Das „AUTO_INCREMENT“ kommt i.d.R. zusammen mit dem „primary key“: „automatic increment by 1“.
4. Das Insert-Statement
4.1. Insert innerhalb einer Tabelle
- Insert eine Zeile mit allen Spalten:
INSERT INTO tabelle_name VALUES (wert_spalte1, wert_spalte 2, …, wert_spalten)
Insert einer Zeile in eine Tabelle_beispiel 1
- Insert eine Zeile mit bestimmten Spalten:
INSERT INTO tabelle_name (spalte1, spalte2) VALUES (wert_spalte1, wert_spalte 2)
Insert einer Zeile in eine Tabelle_beispiel 2
- Insert mehrere Zeilen in einer Tabelle:
INSERT INTO tabelle_name (spalte1, spalte2) VALUES (wert_spalte1, wert_spalte 2), (wert_spalte1, wert_spalte 2)
Insert mehrerer Zeilen in eine Tabelle_beispiel 3
- Erklärungen
1) DEFAULT: Wenn wir eine Nummer als id_token einfügen, die es aber schon in der Tabelle gibt, wird es misslingen (weil id_token mit dem golden Schlüssel markiert ist). Aber wenn wir den DEFAULT-Wert eingeben, übergeben wir MySQL das Recht, automatisch einen anderen einzigen Wert zu produzieren.
2) Wenn man in eine Spalte keinen bestimmten Wert („leeren Wert“; NULL – KEINEN Wert) einfügen will, die aber NICHT NULL markiert ist, soll man „empty string“ ('') für string-Typ, 0 für numerischen Typ, „zero“ für Datum- und Zeit-Typ einfügen.
4.2. Insert zwischen mehreren Tabellen
Wenn man Zeile(n) in einer Tabelle in eine andere Tabelle einfügen will, muss die Struktur der zwei Tabellen gleich sein.
- Fügen alle Zeilen in Tabelle 1 in die Tabelle 2:
INSERT INTO tabelle2 (spalte1, spalte2, spalte3, … spalten) SELECT spalte1,spalte2, spalte3, …, spalten FROM tabelle1
Insert aller Zeilen einer Tabelle in eine andere Tabelle_1
-- oder INSERT INTO tabelle2 SELECT * FROM tabelle1

Insert aller Zeilen einer Tabelle in eine andere Tabelle_2
- Fügen bestimmte Spalten in Tabelle 1 in die Tabelle 2:
INSERT INTO tabelle2 (spalte1, spalte2) VALUES spalte1, spalte2 FROM tabelle1

Insert bestimmter Zeilen einer Tabelle in eine andere Tabelle
-
Fügen bestimmte Spalten in Tabelle 1 in die Tabelle 2 unter bestimmten Bedingungen:
INSERT INTO tabelle2 (spalte1, spalte2) SELECT spalte1, spalte2 FROM tabelle1 WHERE … ORDER BY …

Insert bestimmter Zeilen einer Tabelle in eine andere Tabelle unter bestimmten Bedingungen
- Vorschlag:
Wie am Anfang schon erwähnt, kann man in SQL nicht rückgängig arbeiten. Deshalb kann man zuerst das SELECT ... durchführen, und erst wenn man die erwünschten Ergebnisse bekommt, schreibt man vor dem SELECT-Statement dann das INSERT-Statement.
4.3. Eine Frage
Wie kann man zwischen zwei Zeilen eine neue Zeile einfügen?
Zum Beispiel möchten wir in Beispieltabelle "beispiel_tokens_neu" eine neue Zeile 5 (nämlich "id_token = 5") mit dem token "netten" einfügen, in der es aber schon eine Zeile mit "id_token" 5 gibt. Wenn man folgende Kommandos ausführen lässt,
INSERT INTO beispiel_tokens_neu (id_token, token, wortart, lemma) VALUES (5, 'netten', '', '') -- ERROR
zeigt SQL einen Fehler, weil id_token mit "primary key" markiert ist. Deshalb muss man zuerst die eigentliche id_token 5 in 6 und id_token 6 in 7 usw. setzen, für das man das update-statement braucht. Deshalb wird diese Frage erst nach der Erklärung des update-Statements beantwortet.
5. Das Update-Statement
5.1. UPDATE ... SET ...
- update eine Zeile in einer Tabelle unter bestimmten Bedingungen:
UPDATE tabelle_name
SET …
WHERE …
-- z.B. UPDATE queries
SET titel = 'Guten Morgen'
WHERE id_query = 3
- update mehrere Zeile in einer Tabelle mit dem gleichen Wert:
z.B. UPDATE queries
SET titel = 'Schönen Tag'
WHERE id_query IN (4,5)
Exkurs: IN-Operator
SELECT * FROM beispiel_tokens_neu WHERE wortart = 'NN' OR wortart = 'ART' OR wortart = 'APPR' -- WHERE wortart IN ('NN', 'ART', 'APPR') -- WHERE wortart NOT IN ('NN', 'ART', 'APPR')
IN-Operator und REPLACE-Funktion
- Kurzer Weg: Doppelklick >> Einfügen
5.2. Fragebeantwortung
UPDATE beispiel_tokens_neu SET id_token = id_token + 1 WHERE id_token >= 5 ORDER BY id_token DESC; INSERT INTO beispiel_tokens_neu (id_token, token, wortart, lemma) VALUES (5, 'netten', '', '') -- UPDATE-Statement und INSERT-Statement werden durch Strichpunkt getrennt.
Wenn wir eine neue Zeile 5 einfügen möchten, müssen die Zeilen ab der eigentlichen 5. Zeile eine Zeile nach unten rutschen, d.h. man soll id_token ab 5 plus 1 machen. Aber z.B. wenn man die eigentliche 5. Zeile (mit id_token 5) plus 1 macht, bekommt man die neue id_token 6, die es aber schon in der Tabelle gibt (nämlich die eigentliche 6. Zeile mit id_token 6). Aber wenn man die id_token absteigend plus 1 macht, nämlich von der letzte id_token 393 an plus 1 machen, und dann 392 + 1, 391 + 1, ... 5 + 1, taucht kein Problem auf. Deshalb benutzen wir ORDER BY id_token DESC.
6. Das Delete_Statement
- Löschen Zeile(n) in einer Tabelle:
DELETE FROM tabelle_name WHERE ...

Delete Zeilen in einer Tabelle unter bestimmten Bedingungen
- Kurzer Weg
Delete_kurzer Weg
7. Create/Alter Table
7.1. Kopieren einer Tabelle
1) Nur Struktur, Struktur und Daten, Nur Daten (Wie oben schon erwähnt, ist die Struktur einer Tabelle sehr wichtig, wenn man eine Zeile in Tabelle 1 in die Tabelle 2 einfügen möchte.)
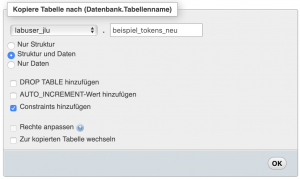
Kopieren einer Tabelle
2) durch:
CREATE TABLE tabelle_kopie AS SELECT * FROM tabelle_name
Achtung!: nicht alle „column attributes“ werden wie original korpiert.
3) CREATE TABLE … LIKE-Statement:
Eine leere Tabelle wird erzeugt, deren Spalten, Spaltenattribute und Indizes gleich wie in der originalen Tabelle.
CREATE TABLE tabelle_kopie LIKE original_tabelle
4) CREATE TABLE … SELECT-Statement: kopieren bestimmter Spalten in einer Tabelle in die neue Tabelle:
CREATE TABLE tabelle_kopie AS SELECT spalte_x, spalte_y, spalte_z FROM original_tabelle [WHERE … ORDER BY … LIMIT …]
7.2. Erzeugen einer neuen Tabelle
1) Datenbank (siehe Abb. 17) >> Operationen >> Erzeuge Tabelle (Name, Anzahl der Spalten) >> OK (siehe Abb. 18) >> Abb. 19
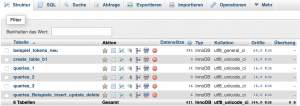
Erzeugen einer neuen Tabelle in einer Datenbank_Schritt 1
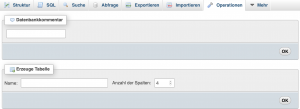
Schritt 2
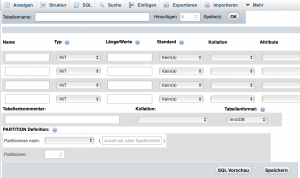
Schritt 3
2) CREATE TABLE -Statement:
CREATE TABLE tabelle_name ( spalte1 dateityp NOT NUll AUTO_INCREMENT, spalte2 dateityp … , spalte3 dateityp … , … spaltex dateityp … , PRIMARY KEY (spalte_name) ) -- siehe Abb. 3
Oder:
CREATE TABLE tabelle_name ( spalte1 dateityp PRIMARY KEY, spalte2 dateityp, spalte3 dateityp, … spaltex dateityp)
7.3. Umbenennt einer oder mehrerer Tabellen
RENAME TABLE tabelle1_name TO tabelle1_name_2, tabelle2_name TO tabelle2_name_2
7.4. Löschen einer Tabelle
DROP TABLE tabelle_name
Oder: ein kurzer Weg
Löschen einer Tabelle
7.5. VIEW oder Table?
Ein View zu erzeugen ist ganz analog zu „create table“.
CREATE VIEW tabelle_view AS SELECT * FROM tabelle [WHERE …]
Der Unterschied zwischen View und Tabelle:
View ist eine virtuelle und temporal generierte Tabelle. Man kann unterschiedliche Daten aus verschiedenen Tabellen in ein View zusammenstellen, und wenn Daten in den entsprechenden Tabellen verändert sind, werden die entsprechenden Daten im View auch automatisch aktualisiert, auch umgekehrt. Man kann kein Indiz (engl. "index") in ein View setzen.
8. Index
Index in SQL funktioniert ähnlich wie ein Index in einem Buch. Wenn man etwa bestimmtes in einem Buch durchsucht, braucht man nicht das ganze Buch durchzulesen, stattdessen kann man in einem Index schneller suchen. Mithilfe von Index wird die Suche in SQL sehr beschleunigt, wenn man eine große Menge von Daten bearbeiten muss. Im folgenden werden drei grundlegende Indizes vorgestellt:
- primary key (Primärschlüssel): ein Identifikator, natürlich unique markiert.

- key: ein normales Indiz.

- Unique:

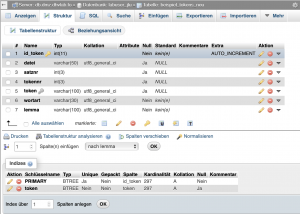
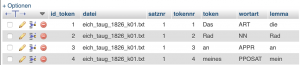
Indizes in Tabelle "beispiel_tokens_neu"
In der Tabelle "beispiel_tokens_neu" gibt es insgesamt zwei Indizes: eines ist Primärschlüssel in der Spalte "id_token", das andere ist ein normales Indiz in der Spalte "token".
9. Mehr Erklärungen unter
insert: https://dev.mysql.com/doc/refman/8.0/en/insert.html
update: https://dev.mysql.com/doc/refman/8.0/en/update.html
delete: https://dev.mysql.com/doc/refman/8.0/en/delete.html
allgemeines: https://dev.mysql.com/doc/refman/8.0/en/sql-data-definition-statements.html