Tesseract ist eine der bekanntesten Softwares im Bereich der Optical Character Recognition. In diesem Beitrag werden Codebeispiele vorgestellt und erläutert, mithilfe derer automatisch Text aus Bildern erkannt und als String ausgegeben werden kann. Dies erweist sich bei der Digitalisierung von Texten als sehr nützlich.
In diesem Beispiel soll eine Anzeige aus dem Amerika des ca. 17.- 19. Jahrhunderts digitalisiert werden. Der originale Text sieht so aus:

Der zu bearbeitende Text: Eine Anzeige aus dem Amerika des 17.-19. Jahrhunderts.
Als Programmierumgebung wurde hier Jupyter Notebook verwendet. Vor dem Programmierprozess lädt man die Software Tesseract z.B. hier herunter. Außerdem benötigt man einige Python-Zusatzpakete, die ebenfalls im Vorfeld installiert werden müssen: opencv und pytesseract. Opencv wird für die Bildbearbeitung eingesetzt, pytesseract für die Texterkennung.
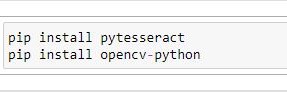
Der Code, um die Python-Zusatzpakete pytesseract und opencv zu installieren.
Daraufhin werden aus verschiedenen Bibliotheken die Module importiert, die im darauffolgenden Code benötigt werden: aus dem frisch installierten opencv das Modul cv2, außerdem pytesseract, numpy, os und re. Numpy wird für Berechnungen eingesetzt, os verwendet man, um Ordnerstrukturen anzulegen, und re ist die Standardbibliothek für reguläre Ausdrücke.
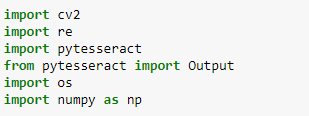
Die im Anschluss benötigten Python-Bibliotheken werden importiert.
Bevor man mit dem eigentlichen Programmieren beginnen kann, muss man außerdem noch die davor installierte Tesseract-Software installieren - die nicht identisch mit dem davor installierten Python-Paket pytesseract ist. Dafür verwendet man folgenden Ausdruck:
pytesseract.pytesseract.tesseract_cmd = r"Dateipfad zur .exe-Datei aus dem Tesseract- Download“
Im Beispiel sieht das so aus:
Die Software Tesseract, die man davor heruntergeladen hat, wird installiert.
Der Text, der digitalisiert werden soll, liegt am Anfang als Bild vor, am besten als .png- oder -tif-Datei. Zuerst wird dieses Bild eingelesen.
Das Bild wird ausgegeben.
Wenn man sich das Bild ausgeben lassen will, funktioniert verwendet man zuerst den Befehl cv2.imshow (analog zur print-Funktion bei Strings). Daraufhin gibt man in der cv2.waitKey-Funktion eine Zeitangabe in Sekunden an; solange soll das Bild angezeigt werden. Um das Bild dann wieder zu schließen, verwendet man cv2.destroyAllWindows(). Dieser Code kann in jedem Stadium des Programmierprozesses eingesetzt werden, wenn man sehen möchte, wie das Bild verändert wurde. Konkret:
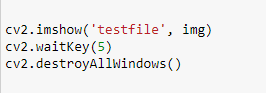
Das Bild wird geöffnet, 5 Sekunden angezeigt und dann wieder geschlossen.
Die Funktionen, die im Anschluss definiert werden, dienen dazu, die Texterkennung zu verbessern. Mit convert_grayscale wird das Farbschema auf schwarz-weiß gesetzt. Die Funktion blur dient dazu, das Bildrauschen zu reduzieren und damit die Texterkennung zu verbessern. Mit dem Argument param kann man festlegen, wie stark das Bild vereinfacht werden soll; der Wert param kann nur ungerade Werte größer als 1 annehmen. Durch die Funktion threshold wird das Bild binär gemacht; konkret bedeutet das, dass alle Pixel in dem Bild nur jeweils einen Wert annehmen können.

Die Funktionen convert_grayscale, blur und threshold verbessern die Texterkennung.
Sollen die einzelnen Wörter erkannt werden, verwendet man folgenden Code: den drei Dimensionen (Kanälen) des Bildes werden die Variablen h, w und c zugewiesen (wenn man sich unsicher ist, wie viele Kanäle das Bild aktuell hat, kann man das mit dem Befehl print(img.shape) überprüfen). Mit dem Befehl image_to_boxes wird ein String mit dem Namen boxes erstellt. Über diese Variable wird dann iteriert; die Funktion splitlines bewirkt, dass der String boxes in jeder neuen Zeile getrennt und die einzelnen Elemente in eine Liste geschrieben werden. Mit dem Befehl split wird jedes einzelne Listenelement dann noch am Leerzeichen getrennt. Dadurch wurde jedes Wort einzeln erfasst. Dann wird um jedes Wort ein Kästchen gezogen; die komplizierte Syntax lässt sich am besten so erklären: mit cv2.rectangle kann eingestellt werden, welches Bild, welchen Start- und Endpunkt, welche Farbe für die Umrandung verwendet werden und wie stark die Pixel sein sollen. Das Farbschema ist frei wählbar; unter diesem Link kann man sich verschiedene Schemata anschauen.
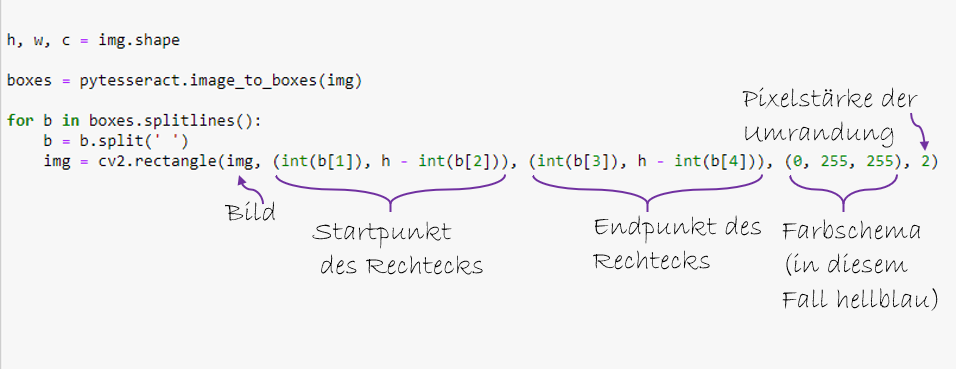
Um jedes Wort wird ein Kästchen gezogen.
Das Endergebnis sieht dann so aus, die meisten Wörter wurden erkannt und umrandet:

Der Text mit den erkannten Wörtern.
Möchte man genauere Informationen über das Bild erfahren, kann man sich ein die Daten in einem Dictionary ausgeben lassen. Interessant ist hier vor allem der sogenannte confidence score (hier mit conf abgekürzt), der angibt, wie hoch die Wahrscheinlichkeit ist, dass das Wort richtig erkannt wurde (im Beispeil lila umrandet). Hier kann man genau sehen, welches Wort welchen confidence score hat; zum Beispiel wurde das Wort "Plantation" mit einer Wahrscheinlichkeit von ca 50% richtig erfasst; unter dem Schlüssel text (auch lila umrandet) sieht man, dass dieses Wort tatsächlich falsch erkannt wurde, denn es wird hier "Plancation" ausgegeben (vgl. die grün umrandeten Stellen). In den folgenden zwei Beispielen sind die confidence scores dagegen sehr hoch - über 90% - und die Wörter wurden auch richtig erkannt.

Ein Dictionary mit Informationen über das Bild wird erstellt und ausgegeben.

Ein Ausschnitt aus dem Output des Dictionarys: Die Schlüssel conf und text sind lila umrandet, die Werte für die ersten drei Wörter jeweils in der gleichen Farbe.
In diesem Codebeispiel sollen nur Wörter mit einem hohen confidence score erfasst werden. Die Variable n_boxes zählt die Anzahl der erkannten Strings; in der darauffolgenden for-Schleife wird n-mal (je nachdem, wie viele Strings die Liste enthält) der oben erläuterte confidence score abgefragt. Ist dieser Wert größer als 60 (also wurde das Wort mit hoher Wahrscheinlichkeit richtig erkannt), soll wieder ein Kästchen um das Wort gezogen werden.
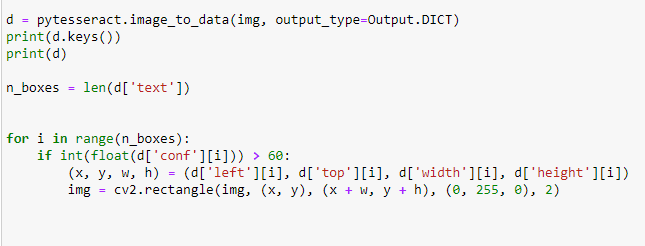
Alle Wörter mit einem confidence score von höher als 60 sollen umrandet werden.
Bei einer spezifischen Fragestellung kann man die wichtigen Wörter mit einem regulären Ausdruck ansteuern: Hier sollen alle Wörter mit einem sogenannten medialen s erkannt und umrandet werden. Ein mediales s findet man in der Mitte oder am Anfang eines Wortes (aber nicht am Schluss); dies wird in dem regulären Ausdruck abgefragt, der als s gespeichert wird. In dem folgenden Konditional sollen alle Wörter erkannt werden, die ein mediales s erhalten und deren confidence score über 60% liegt, dann sollen sie umrandet werden.

Alle Wörter, auf die der reguläre Ausdruck zutrifft und deren confidence score über 60 liegt, sollen umrandet werden.
Man kann sich auch den gesamten Text als String ausgeben lassen. Dafür verwendet man folgenden Code:
Der Text wird als String ausgegeben.
Wenn Tesseract nicht alle Zeichen richtig erkannt hat, muss man es trainieren. Hier findet man eine hilfreiche Anleitung mit einem Shell Script, wie man die Zeichenerkennung verbessern kann. Auf der Website von Tesseract sind außerdem Trainingsdaten für viele verschiedene Sprachen sowie weitere Beschreibungen und Tutorials verfügbar.
Abschließend möchte ich noch anmerken, dass diese Codebeispiele folgender Website entnommen sind und hier nur leicht modifiziert, aber deutlich ausführlicher erklärt wurden. Wer sich selbst an Tesseract versuchen will, sollte sich bewusst machen, dass es nicht funktionieren wird, den Code einfach zu kopieren. Man muss Schritt für Schritt vorgehen, versuchen, den Code nachzuvollziehen und ihn vor allem an seine eigenen Bedürfnisse und an die Technik seines Computers anpassen.