1. Zeichenkodierung in der Digitaltechnologie
- Computer arbeiten ausschließlich mit binären Zahlen, also Nullen und Einsen. Zur Verwendung von Schriftzeichen aller Art auf Computern, ist daher eine Zuordnung von Zeichen zu Zahlen erforderlich. Man kann das auch als "Kodierung" bezeichnen.
- Um elektronische Daten austauschen zu können, ist ein verbindlicher Standard nötig, der genau festlegt, welche Zahl für welches Zeichen steht.
- Seit Erfindung des Computers wurden mehrere solcher Standards entwickelt und verwendet.
- Einer der ältesten und bis heute verwendeten Standards ist der American Standard Code for Information Interchange (ASCII).
- Seit Anfang der 90er Jahre gibt es Unicode, das sich mehr und mehr durchsetzt.
- Auch und gerade in der Korpuslinguistik ist die Verwendung einer einheitlichen Zeichenkodierung unverzichtbar.
1.1. ASCII
American Standard Code for Information Interchange, Erstveröffentlichung am 17. Juni 1963, letzte Aktualisierung im Jahr 1968. Seither stabil. 7-Bit-Kodierung ⇒ 128 Zeichen kodierbar.
1.2. Übersicht 1 (Auszug aus der ITG-Unicode-Datenbank):
NO QUERY GIVEN!
1.3. Übersicht 2:
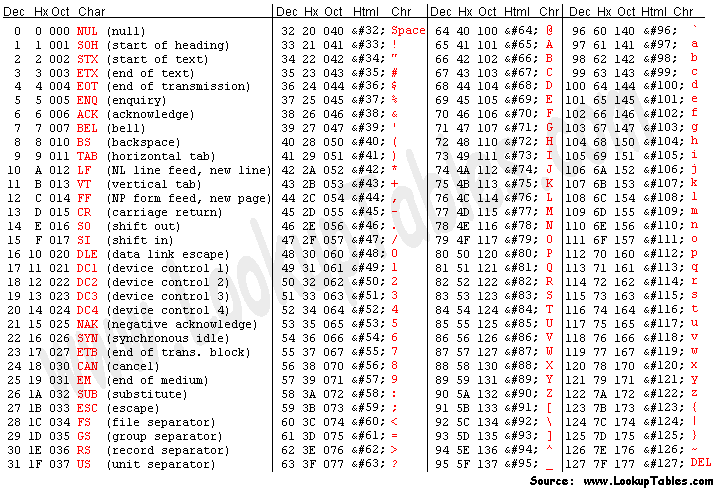
ASCII-Tabelle
1.4. Unicode
Eine Codepage, die die bei der Zahl 127 endende Liste des ASCII-Codes nach oben öffnet und erweitert (Version 1.0.0 erschien im Oktober 1991). Die Unicodetabelle endet derzeit (2015) bei der dezimalen Zahl 1.114.109, d.h. Unicode bietet theoretisch Raum für über eine Million zu kodierende Zeichen. Aktuell (Oktober 2015) sind rund 120.000 Zeichen definiert.
1.4.1. Die Unicode-"Plains"
- Der von Unicode umfasste Zahlenraum ist nach arithmetischen Kriterien in sog. "Plains" ("Ebenen") unterteilt:
NO QUERY GIVEN!
1.4.2. Die Unicode-Blöcke
Neben der Gliederung in Plains besteht innerhalb von Unicode eine Unterteilung in Blöcke, die sich an den Kategorien der kodierten Zeichensysteme orientiert:

Die folgende Grafik (Quelle: Wikipedia) veranschaulicht sehr schön die systematische Verteilung der Schriftsysteme im Schema der Unicode-Plains:
{kind=link}
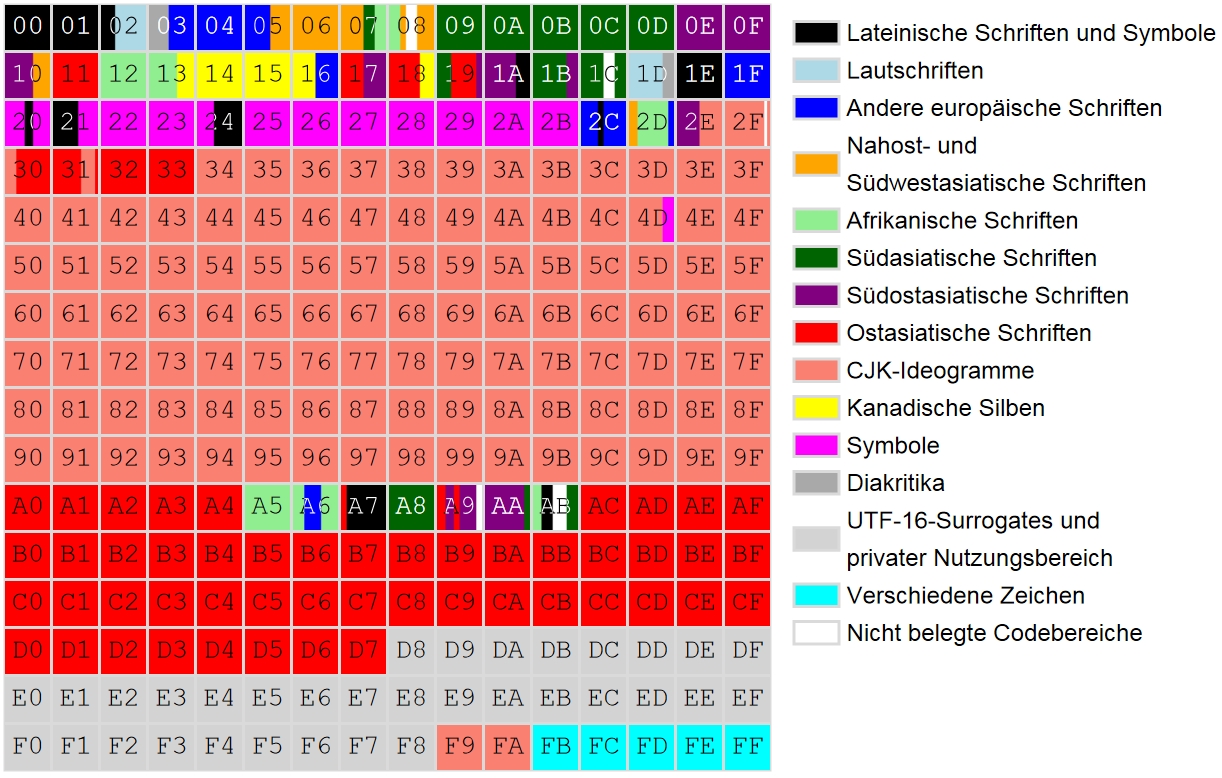
Übersicht über die Unicode-Plains
1.4.3. UTF-8
Für die Abbildung der von Unicode verwendeten Zahlen auf die von Computern ausschließlich verwendeten und jeweils zu Einheiten von acht "Bits" zusammgefassten binären Zahlen wurden verschiedene Verfahren entwickelt, die man als "Unicode Transformation Formats" (UTF) bezeichnet. Das derzeit am weitesten verbreitete UTF ist UTF-8.
1.5. Kodierung des Zeilenendes
Das Ende einer Textzeile wird bis heute von verschiedenen Betriebssystemen unterschiedlich kodiert.
Semantisches Paradigma ist die Schreibmaschine:
Der folgende Haiku wurde der Webseite https://de.wikipedia.org/wiki/Haiku entnommen und in jeweils einer Windows- und einer Unix-kodierten Textdatei abgespeichert. Das Unix-Kommando xxd erlaubt die hexadezimale Darstellung der Dateiinhalte (sog. "Hexdump"). Haiku:
Ab der Mittagszeit ist es etwas schattiger ein Wolkenhimmel
Windows: 0d 0a (= CR LF = \r\n) (Datei haiku_windows_0d0a):
slu@PCROMLAB1301:Texte$xxd -g 1 haiku_windows_0d0a.txt 0000000: 41 62 20 64 65 72 20 4d 69 74 74 61 67 73 7a 65 Ab der Mittagsze 0000010: 69 74 0d 0a 69 73 74 20 65 73 20 65 74 77 61 73 it..ist es etwas 0000020: 20 73 63 68 61 74 74 69 67 65 72 0d 0a 65 69 6e schattiger..ein 0000030: 20 57 6f 6c 6b 65 6e 68 69 6d 6d 65 6c 0d 0a Wolkenhimmel..
Unixsysteme inklusive Mac OS X: 0a (= LF = \n) (Datei haiku_unix_0a):
slu@PCROMLAB1301:Texte$xxd -g 1 haiku_unix_0a.txt 0000000: 41 62 20 64 65 72 20 4d 69 74 74 61 67 73 7a 65 Ab der Mittagsze 0000010: 69 74 0a 69 73 74 20 65 73 20 65 74 77 61 73 20 it.ist es etwas 0000020: 73 63 68 61 74 74 69 67 65 72 0a 65 69 6e 20 57 schattiger.ein W 0000030: 6f 6c 6b 65 6e 68 69 6d 6d 65 6c 0a olkenhimmel.
In beiden Texten ist das Wort "schattiger" unterstrichen. Im Fall der Windows-kodierten Datei besteht die Gefahr, dass der 0d-Wert bei einer automatisierten Tokenisierung durch ein Unix-System (auch Cygwin) als Bestandteil des Wortes "schattiger" betrachtet wird. Eine entsprechende Tokenliste sähe dann folgendermaßen aus (die Zahlenwerte 20 [= Blank] und 0a fungieren als Separatoren und sind daher verschwunden):
41 62 Ab 64 65 72 der 4d 69 74 74 61 67 73 7a 65 69 74 0d Mittagszeit 69 73 74 ist 65 73 es 65 74 77 61 73 etwas 73 63 68 61 74 74 69 67 65 72 0d schattiger 65 69 6e ein 57 6f 6c 6b 65 6e 68 69 6d 6d 65 6c 0d Wolkenhimmel
Eine Suche nach dem Wort "schattiger" in o.a. Tokenliste würde keinen Treffer ergeben, da keine exakte Übereinstimmung in der numerischen Repräsentation zwischen Suchmuster und gespeichertem Token vorhanden ist:
Suchmuster Token
73 63 68 61 74 74 69 67 65 72 73 63 68 61 74 74 69 67 65 72 0d
Das selbe Phänomen/Problem träte im gegebenen Beispiel auch bei den Tokens "Mittagszeit" und "Wolkenhimmel" auf.
Manche, heute kaum noch verwendete Betriebssysteme wie z.B. ältere Apple-Betriebssysteme (bis Version 9), kodieren das Zeilenende auch mit einem einzelnen 0d. Auch wenn diese Betriebssysteme selbst nicht mehr eingesetzt werden, kann es sein, dass es noch entsprechende Dateien gibt.
1.6. Hilfsmittel beim Umgang mit Zeichenkodierung
- Vim (:se fenc; :se ff; Tastenkombination ga)
- Linux-Kommandos file, iconv, od, xxd (verfügbar im Virtuellen Desktop des DHVLab)
- Webseiten:
1.7. Konfiguration des Editors VIM
Die folgenden VIM-spezifischen Einstellungen beeinflussen das Verhalten dieses Editors im Umgang mit der Zeichenkodierung:
# Datei in utf-8-Kodierung :se fileencoding=utf-8
# Datei mit Kodierung des Zeilenendes nach Windows-Konvention: :se fileformat=dos # Datei mit Kodierung des Zeilenendes nach Windows-Konvention: :se fileformat=unix
# Datei ohne BOM :se nobomb # Datei mit BOM :se bomb
Empfehlenswerte Standardeinstellungen für den Editor Vim sind in folgender Konfigurationsdatei enthalten (muss im Homeverzeichnis abgelegt werden):
Für Windowsrechner: http://www.kit.gwi.uni-muenchen.de/wp-content/uploads/2015/03/_vimrc
Für Linux/Unixrechner: http://www.kit.gwi.uni-muenchen.de/wp-content/uploads/2015/03/.vimrc
Auch Microsoft Word erlaubt beim Speichern von reinen Textdateien ("Speichern unter..." ⇒ "Nur Text") die Beeinflussung der Zeichen- und Zeilenendkodierung:
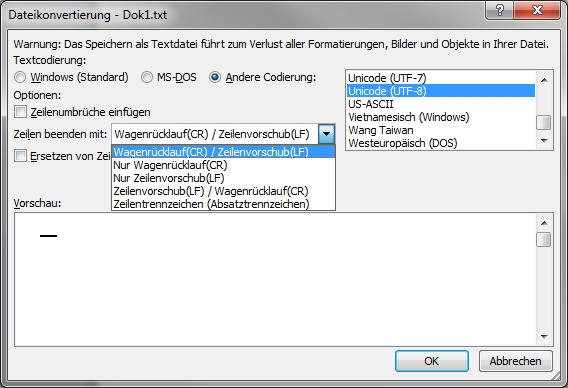
Dialogfeld von Microsoft Word zur Einstellung der Zeichenkodierung
2. Blick in die Geschichte: Zeichenkodierung in der prädigitalen Zeit
2.1. Der Fall Trojas
Aischylos (griechischer Tragiker, 525 - 456 v. Chr.), Agamemnon (aufgeführt 458 v. Chr.): Die Nachricht vom Fall Trojas wird mittels Feuerzeichen nach Argos im griechischen Mutterland übertragen.
Ganz zu Beginn der Tragödie spricht ein Wächter:

καὶ νῦν φυλάσσω λαμπάδος τὸ ξύμβολον, αὐγὴν πυρὸς φέρουσαν ἐκ Τροίας φάτιν / ἁλώσιμόν τε βάξιν·
Übersetzung: "And now I’m looking out for the agreed beacon-signal, the gleam of fire bringing from Troy the word and news of its capture" (Text und Übersetzung Ed. Loeb.)
Die Übertragung des Lichtsignals über insgesamt rund 550 km erfolgt in mehreren Etappen, häufig von Bergspitzen aus (Aisch. Agam. 281-309).
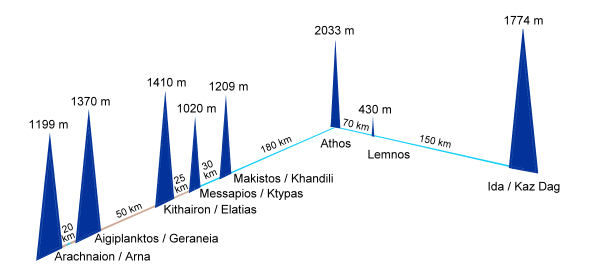
Schema der Übertragung der Nachricht vom Fall Trojas durch Signalfeuer (Quelle: https://commons.wikimedia.org/w/index.php?title=File:Feuerpost,_-_fire_beacon_-_Aischylos_-_Illustration.png&oldid=460140584 [CC BY-SA 3.0 unported])
{kind=link}
Auch hier liegt eine Kodierung vor: Ein vereinbartes Zeichen übermittelt eine Information. Wichtig: Sender und Empfänger müssen beide die Bedeutung des Zeichens kennen.
2.2. Polybios-Chiffre
Wird die Bedeutung der Zeichen in einem Kodierungssystem geheim gehalten, so spricht man von Chiffrierung. Dies ist immer dann nötig, wenn übertragene Nachrichten nicht von jedermann, sondern nur von ausgewählten Empfängern verstanden werden sollen. Der Kodierungsschlüssel ist dann jeweils nur Sender und Empfänger bekannt.
Über ein entsprechendes System berichtet bereits der griechische Geschichtsschreiber Polybios (* um 200 - 120 v. Chr.; Hist. 10,45,6).
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| 1 | A | B | C | D | E |
| 2 | F | G | H | I | K |
| 3 | L | M | N | O | P |
| 4 | Q | R | S | T | U |
| 5 | V | W | X | Y | Z |
Anstelle der Buchstaben werden deren Koordinaten übermittelt:
Polybios -> 35 34 31 54 12 24 34 43
2.3. Murray Shutter Telegraph

Codepage des Murray Shutter Telegrafs (Schautafel des National Trust - Birling Gap and the Seven Sisters)
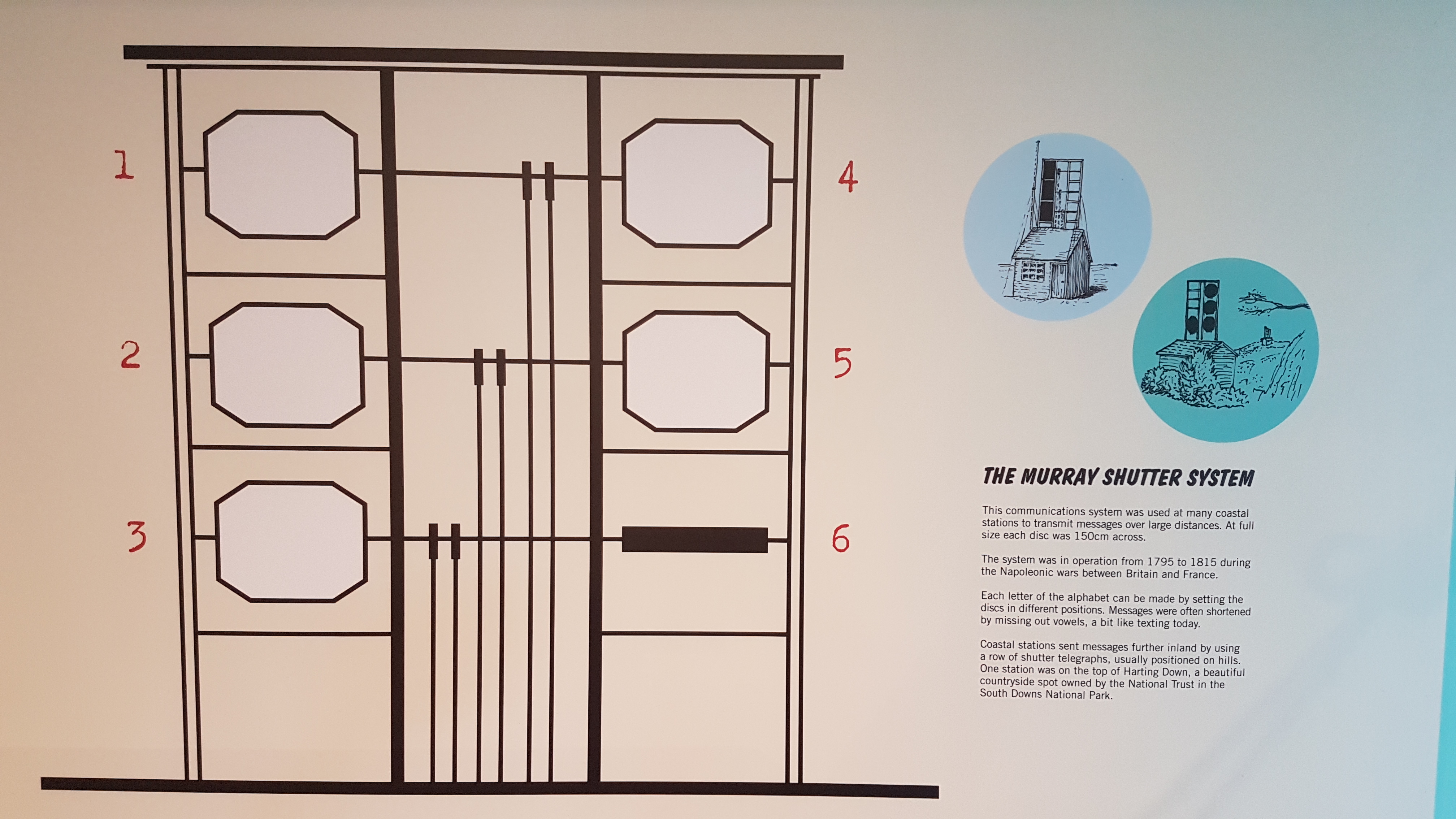
Mechanische Funktionsweise des Murray Shutter Telegrafs (Schautafel des National Trust - Birling Gap and the Seven Sisters)
2.4. Morsecode
Eine sehr frühe Form (Samuel Morse, 1833) der Zeichenkodierung liegt im Morsecode vor, der dafür gedacht war, Schriftzeichen unter Verwendung analoger Kanäle (Licht, Schall, elektrischer Strom) zu übermitteln. Das deutsche Wort "SÜß" sieht in Morsekodierung folgendermaßen aus (ein Punkt steht für ein kurzes [sog. "dit"], ein Strich für ein langes Signal ["dah"]; eine Unterscheidung zwischen Groß- und Kleinbuchstaben ist nicht möglich): · · · <pause> · · − − <pause> · · · − − · ·
| S | Ü | ß |
|---|---|---|
| · · · | · · − − | · · · − − · · |
Die Länge eines "dah" beträgt die Länge von genau drei "dit". Zwischen den Zeichen erfolgt eine Pause ("Schweigen") von genau einem "dit". Zwischen Wörtern wird eine Pause von sieben "dit" eingefügt. Im Unterschied zur digitalen Informationskodierung, die mit einem Signalrepertoire von nur zwei Zeichen auskommen muss (0,1), stehen demnach im Morsecode drei "Zeichen" zur Verfügung: dit, dah, Pause. Nur deshalb können im Morsecode, anders als bei digitaler Informationskodierung, Zeichen durch eine jeweils unterschiedliche Anzahl an Zeichen kodiert werden (· = E; − · − − = Y).