
/var/cache/html/dhlehre/html/wp content/uploads/2017/10/1508825341 Catania QR
1. Panoramica
1Negli ultimi anni abbiamo sviluppato una piattaforma virtuale che suddivide le attività academiche in tre settori:
- i progetti scientifici dei membri dell'ateneo;
- l'insegnamento accademico;
- la pubblicazione scientifica.
Da un punto di vista tecnico e tecnologico questo processo è stato implementato dal centro di umanistica digitale della LMU (ITG) e i contenuti risultano dalla stretta cooperazione con le discipline coinvolte. Il funzionamento viene continuamente ottimizzato sulla base delle esperienze degli utenti. I tre settori sono accessibili da tre siti distinti che, però, utilizzano lo stesso software e possono essere collegati facilmente tra di loro. L'architettura informatica è fondata su database relazionali di tipo MySQL e su superfici web create con il software WordPress, che permette di scrivere direttamente sul server (come pure il presente contributo). I tre settori si distinguono traf die lor per la loro complessità interna (più grande nel caso [i]), per la pragmatica (didascalica nel caso [ii]) e per la loro accessibiltà (senza restrizioni nel caso [iii]).
2. Settore progetti autonomi
Questo settore racchiude progetti molto diversi tra loro e appartenenti a varie discipline: storia, storia dell'arte (1, 2), storia del teatro, musicologia (1, 2), egittologia/coptologia (1, 2, 3), diverse filologie e linguistiche, ebraistica/teologia, uralistica, slavistica e - ovviamente - la romanistica con l'italianistica (1, 2, 3, 4, 5). Per illustrare alcune opzioni, che non sono offerte da tutti i siti appena elencati, presentiamo il progetto etnolinguistico e plurilingue VerbaAlpina, diretto dall'autore assieme a Stephan Lücke.
Per comprenderne la concezione è importante tener conto che il progetto doveva corrispondere alle nuove condizioni della comunicazione scientifica nel web. I compiti e le prestazioni di VerbaAlpina possono essere assegnati a cinque ambiti:
2.1. (1) Documentazione
La documentazione comprende molte fonti già pubblicate (atlanti linguistici e dizionari dialettali). Il lessico dialettale, che è valutato come caratteristico conformemente alla cornice onomasiologica, è stato selezionato, retrodigitalizzato e trasformato in dati strutturati ed etichettati. Questi dati sono accessibili al pubblico tramite una visualizzazione cartografica con filtri onomasiologici, semasiologici, etimologici ed extralinguistici.
2.2. (2) Cooperazione
Il web permette di coinvolgere facilmente partner, anche numerosi, a condizione che il software sia compatibile o almeno convertibile. Si tratta sicuramente di uno dei vantaggi più convincenti della umanistica digitale. Anche VerbaAlpina ha numerosi partner legati da convenzioni stabilite; ogni partner ha la possibilità di gestire un proprio database nell'ambiente del progetto, come mostrato nella foto seguente:
Sigla 'pva_nn' = 'partner VerbaAlpina nn'
Tuttavia, non è da sottovalutare il rischio derivante dalla compartecipazione di aziende private, spesso coinvolte a causa la mancanza di strutture universitarie adeguate. Alcuni progetti, soprattutto lessicografici, hanno perso i diritti di disporre liberamente dei (propri) dati, i quali sono stati ceduti all'insaputa dei ricercatori.
2.3. (3) Pubblicazione
Quando un progetto applica tecnologie web, il significato del termine pubblicazione è sostanzialmente cambiato perché internet non è altro che una gigantesca macchina di pubblicazione; un progetto a codice sorgente aperto ('open source'), quindi, rende pubblico necessariamente lo stesso codice, i dati empirici salvati e i metadati corrispondenti. Naturalmente è possibile pubblicare sullo stesso sito anche testi analitici, cioè 'pubblicazioni' in senso tradizionale (ved. contributi). Questa forma, contrariamente alla stampa, permette di inserire audio file, video, link e - una opzione importantissima - di gestire direttamente richieste dei database progettuali.
2.4. (4) Rilevamento dei dati
Internet non serve solo per dare accesso a documentazioni e discorsi analitici; apre anche nuove forme per rilevare dati attraverso il cosiddetto crowdsourcing come illustra l'implementazione dell'applicazione Partecipare!
Tutti gli ambiti vengono ampliati e elaborati continuamente. Una ulteriore funzione è in preparazione:
2.5. (5) Laboratorio di ricerca
Esso invita tutti gli utenti interessati a utilizzare individualmente gli strumenti geolinguistici sviluppati da VerbaAlpina (diverse raffigurazioni cartografiche, livelli di tipizzazione ecc.) e di presentare nuovi risultati e analisi, forse anche alternativi.
3. Settore insegnamento
Attualmente due siti supportano l'insegnamento; dato che rappresentano anche due 'generazioni' si aspetta l'integrazione del primo nel secondo in una specie di laboratorio virtuale, il quale offre la possibilità di usare e di imparare l'uso di software attuali e efficaci, ad esempio R, senza implementarli sul computer locale.
I corsi che usano queste strutture invitano gli studenti a scrivere tesine sostanzialmente cambiate, come mostrato in modo esemplare nel lavoro di Eva (Huber 2017) sul descord famoso Eras quan vey verdeyar del trovatore Raimbaut de Vaqueiras (♦). Sono qui inseriti molti collegamenti e viene proposto un modello per l'edizione didattica di poesie medievali sotto forma ipertestuale (♦).
3.1. Nuove forme di cooperazione: qualche esempio
Questi quadri mediali producono delle forme di cooperazione molto costruttive e rinforzano la sostenibilità dell'insegnamento e dei lavori condotti dagli studenti. Segue qualche esempio.
3.2. (1) Cooperazione tra studenti e progetti
Alcune lacune o incompletezze dei progetti scientifici possono essere migliorate dagli studenti, sia nel caso in cui queste siano scoperte dagli stessi studenti, sia che vengano suggerite dai docenti. Così, Myriam Abenthum ha scritto commenti lessicologici per VerbaAlpina che sono stati corretti dai direttori del progetto e poi integrati al Lexicon alpinum, cioè al modulo lessicografico; vedi *brod .
3.3. (2) Cooperazione e sviluppo di utilities digitali
Circa un terzo dei dottorandi in linguistica della nostra scuola di dottorato lavora con database relazionali (♦). Tra gli argomenti, che sono molto variegati e seguiti da diversi relatori, ce n'è uno abbastanza innovativo (autore: Sebastian Lasch) focalizzato sulle scritte murali nel comune di Roma. La versione finale presenterà e analizzerà 3000 scritte sotto forma di un atlante urbano interattivo. Tuttavia, la trascrizione del materiale risulta estremamente impegnativa, poiché ogni segno (linguisto o meno) deve essere etichettato in modo analitico e garantire nondimeno la possibilità di risintetizzare gli enunciati in modo corretto. La foto seguente mostra:
- da una prima mano il testo verde Stalin c'è assieme al simbolo della falce e martello;
- da un'altra mano due aggiunte nere che negano il testo in verde: Stalin non c'è più;
- eventualmente da una terza mano (?) due croci celtiche in nero e sovvraposte alle falce e martello;
- sbarre nere su non e più, ovviamente per renderli illegibili in modo da cancellare la negazione;
- infine sovrapposizioni bianche, un simbolo fascista sul nero, che era originalmente verde e una scritta bianca non leggibile sul nome Stalin.

Un muro con scritte a Roma (Foto Sebastian Lasch)
Proprio quando si cercava una soluzione a questa problematica, uno studente di informatica (Daniel Pollithy) era in cerca di un argomento per la sua tesi finale. Si è appassionato del materiale e ha scritto un tool capace di definire l'area sulla foto stessa, di trascrivere e di etichettare le parole sulle aree definite. Ecco come funziona:
Raccolta di informazioni semiotiche su base fotografica (Sebastian Lasch | Daniel Pollithy)
Lo schema dei dati mostra che è non è possibile soltanto annotare categorie semiotiche e precisare le loro relazioni sintattiche (FOLGT 'segue') e microdiachroniche (LIEGT AUF 'sovrapposto a'), ma si possono ulteriormente aggiungere processi mentali ipotetici (AKTIVIERT 'attiva') sotto forma di domini semantici associati (FRAME):
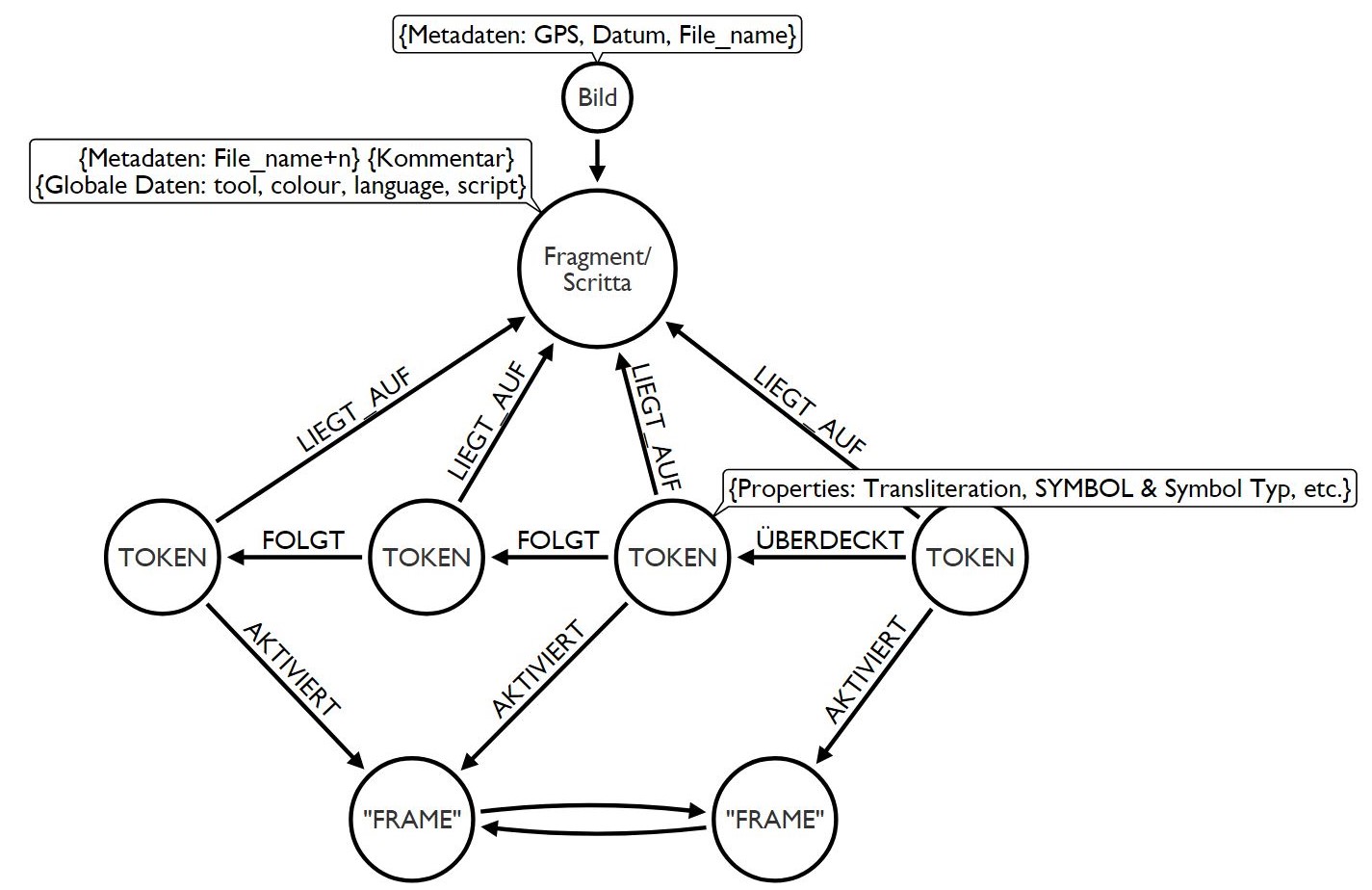
Modello per la raccolta strutturata di scritte murali (Sebastian Lasch | Daniel Pollithy)
Viene usato un graph database (la Community-Edition di Neo4j GraphDB) che permette l'esportazione dei dati nel modello relazionale MySQL degli altri progetti. Il tool sarà implementata nel DHVLab e così messo a disposizione degli utenti. Gioverà molto per progetti epigrafici, editoriali e ben altri ancora.
3.4. (3) Cooperazione e sostenibilità dei corpora e repositori digitali
Una regola fondamentale dell'ambiente virtuale esige che un corpus elaborato da uno dei partecipanti e con il supporto dei docenti rimanga nei repositori del centro di umanistica digitale, in modo da essere sempre allargato, e dettagliato. Recentemente, Katharina (Jakob in prep.) ha difeso la sua tesi di dottorato sulla variazione linguistica mediale in WhatsApp. Ne risulta un corpus con 43583 enunciati che sarà elaborato in futuro dai nostri studenti di linguistica italiana.
Altri progetti di dottorato sono fondati su altri generi testuali o discorsi, ad esempio quello di Sara Ingrosso (in prep.) su biografie linguistiche in contesto migratorio o quello di Jenny Robins (in prep.) sui più antichi testi medicinali stampati (i cosiddetti incunaboli) che sono stati digitalizzati con un software per il riconoscimento ottico dei caratteri (OCR).
/var/cache/html/dhlehre/html/wp content/uploads/2017/10/1508831930 Robins Jenny Pest 1
Questo tipo di corpus cronoreferenziato potrebbe essere arricchito di testi medicinali di altre epoche e di testi aventi altre tematiche, ma risalenti alla stessa epoca ecc. Il corpus delle biografie linguistiche comprende attualmente solo testi di italiani residenti in Germania e sarà senza dubbio interessante estenderlo ad altre lingue e/o altre situazioni socio-politiche.
4. Settore pubblicazione
I settori dei progetti e dell'insegnamento includono gia l'opzione di pubblicare dati e/o testi senza restrizioni d'accesso, ad esempio per corsi monografici (ted. Vorlesungen) e tesi d'esame (ted. Abschlussarbeiten). Il terzo settore però si dedica esclusivamente a questo scopo. Il titolo del sito, Korpus im Text (KiT; it. 'corpus nel testo') delimita la cornice. Vengono accettati lavori che si riferiscono direttamente a corpora ospitati di preferenza sugli stessi server. Attualmente esistono due formati, uno per testi che corrispondono agli articoli su rivista (ted. Artikel) e un altro per testi più lunghi o collezioni d'articoli con una tematica ben definita (ted. Bände). Questo settore, ovviamente, è aperto a tutti linguisti interessati e l'uso di altre lingua è cosa molto gradita.
Si notino, finalmente, due aspetti particolari del nostro formato di pubblicazione:
(1) Vengono prodotte esclusivamente versioni testuali fisse, quasi 'congelate', e il numero della versione creata viene indicato nella parte finale dell'URL. Ad esempio, nel riferimento bibliografico seguente è precisato che si tratta della prima versione per "...v=1":
- Endesfelder, Janina (2017): Dialektale Schriftlichkeit in Italien – Schriftliche Realisierung des dialetto romanesco auf der Facebookseite Spotted: „Sapienza" – Università di Roma. Korpus im Text. Version 1 (21.08.2017, 12:09). Url:http://www.kit.gwi.uni-muenchen.de/?p=12179&v=1.
A livello tecnico è impossibile modificare una versione precedentemente pubblicata, a condizione di non crearne una nuova: "...v=2" e cosí via.
(2) Poiché il testo virtuale non conosce pagine, ogni capoverso della pubblicazione viene automaticamente enumerato alla fine della prima riga. Un semplice clic crea una URL che specifica nella parte finale questo numero all'URL ("...p:1"). Pertanto il seguente link http://www.kit.gwi.uni-muenchen.de/?p=12179#p:1 rimanda al primo capoverso dell'articolo precedentemente indicato.