
/var/cache/html/dhlehre/html/wp content/uploads/2017/08/1506083259 QR Niteroi
Speaking in its elementary form, beyond any media support, is bound to space: It is only possible if speaker and hearer are face to face in the same place. Thus, by the way, the history of media progress reflects the continuous effort of mankind to communicate when speaker and hearer cannot share the same place. Since spoken communication is a local event, the places of intense communication are to be seen as the origin of conventionalization of speaking and in the same time - what is paradoxical - of its variation: other places produce other conventions. The variability and multiplicity of human language is evident in space; and whoever wants to understand the dynamics of language variation and language change has to recognise this spatial embedment.
Therefore, the idea to use cartography for the representation of linguistic diversity came up soon with the mapping of other spatial parameters, like topography, geologic stratification, climate zones, population etc. (see. Rabanus 2005, Lameli 2009). The genre of the linguistic atlas, founded by Wenker 1881, evolved into a very successful research line,1 which has permanently been modernised, up to nowadays. Nevertheless, the mapping of dialect forms in a quasi-geomorphologic manner is somewhat disadvantageous, because it suggests and, maybe, even creates a misleading conception of linguistic space, as will be shown in this paper.
Beside this linguistic topic, I want to give a first idea of how to organise a virtual research framework, which offers five main features (for more informations ♦):
- documentation (e.g. the VerbaAlpina mapping function; ♦);
- cooperation (♦);
- open source publishing (♦);
- data collection by crowdsourcing (e.g. VerbaAlpina application; ♦);
- research laboratory.
All these features are directly accessible for teaching as also demonstrated by this paper which is published in the teaching module.
1. Geography and language - the isogloss
Linguistic atlases show the distribution of highly selected and more or less isolated linguistic items as documented in a net of dialectologic investigation points. The common and divergent features represent the relative linguistic similarity of those points and, in a certain sense, the linguistic profile of the investigated areas. Very important for dialect mapping is the concept of isogloss. This term means a line which marks the border of a distribution area (see Bloomfield 1933, chap. 19; Lang 1982, 65-71 and König 2009, 139). Quite soon, one of the pioneers of dialect geography, Carl Haag (see Haag 1898 and Schrambke 2009 98 ff. ), developed a transparent procedure how to draw this line; this method, which is still applied, Goebl 2005, 503), uses simple geometric operations: in atlases, dialect areas are represented by a net of investigation points where data were collected. Thus, the borders of distribution run between those points which show a certain feature and those which lack it. The method now is to divide the investigated area in polygons without leaving any undefined place; each polygon corresponds exactly to one point and the isoglosses have to follow some polygon borderline (traced in blue in the figure below). The procedure is illustrated on the basis of 6 points:
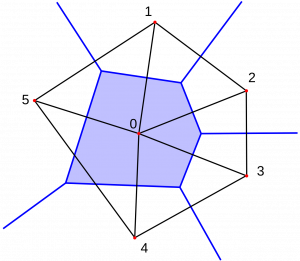
(1) Voronoi-Thiessen-Polygon (https://de.wikipedia.org/wiki/Voronoi-Diagramm#/media/File:Thiessen-Polygon.svg)
- Link the point 0 with all neighbouring points (1-5 ) in order to triangulate the area (black lines);
- drop the perpendicular bisectors on triangle side (blue lines);
- link the intersection points of the perpendicular bisectors and get a polygon with point 0 in its centre;
- color the polygon showing a certain feature (e.g. point 0) and get the visualisation of the area and the corresponding borders.
The application of this method to the variation of a dialect feature of Sicilian illustrates the schematising und idealising power of highly abstract isogloss maps. The definite article masculine singular is realised by two variants, lu vs. u (e.g. in IL SANGUE 'the blood'; detail from 88 (see NavigAIS):
{kind=link}
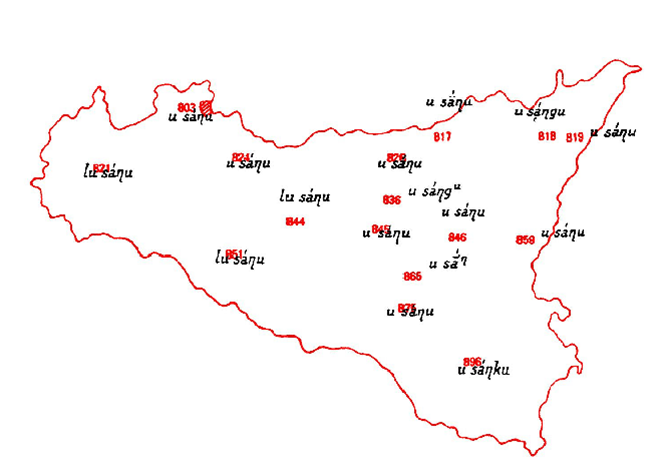
Analytic map: Variation of Sicilian definite article mask. sg. lu vs. u in AIS 88 IL SANGUE ‚the blood‘
Whereas the detail of the original analytic map does not leave any doubt that the data were collected in isolated points, the isogloss map suggests the existence of homogeneous and compact areas and makes forget the weak empirical foundation of those areas which are nothing else but supposed to exist.
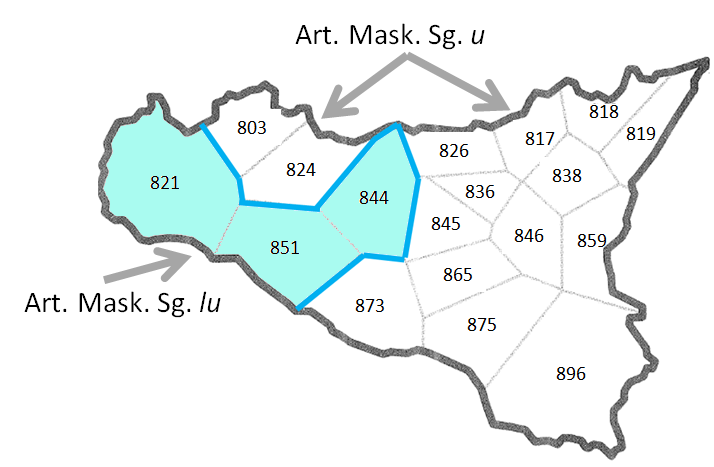
Isogloss map: Variation of Sicilian definite article mask. sg. lu vs. u in AIS 88 IL SANGUE ‚the blood‘
Thus parquetting ("Parkettierung" in Goebl 2005, 503) is particularly good for visualising accumulations of features. Therefore it is fundamental for dialectometrical mapping (♦) elaborated by Hans Goebl and Roland Bauer. Often, the expression 'isogloss' is used in a very broad sense, without any geometric ambition, for lines which are drawn approximatively. A famous example is the 'classical' map of dialects in Italy by Gerhard Rohlfs 1937 (for the polygon version see Krefeld 2016).
What is more important than graphics is the function: isoglosses (not: polygons) are referring always to single features that is to say that they do not represent language or dialect borders. Even in the case of isgloss bundles (some isoglosses with identical course) this is not necessarily true.
To sum up: tracing isoglosses is a traditional means of language mapping; it aims to dissect the tectonics of language areas. But the technique is totally static and inapt to reflect the dynamics and the ecology of communicative space which is not made out of languages but constructed by speakers when they are speaking. Isoglosses conserve a reductionist idea of linguistic space.
1.1. The geography of language - and the speaker
Good atlases indicate biographical data on their informants, concerning age, sex, education level, mobility; the canonical pattern was etablished by the famous Aufnahmeprotokolle of the , which are short proceedings for each point of field research (see Jaberg & Jud 1928, 37-139). All these important details are cut off when isoglosses are extracted. To this, see the two following examples.
1.2. Example (1): Borrowing or bilingual speaker competence?
The first one is a phonetic detail found in the 'speaking' ALD-I ('sprechender' ALD-I); this audio atlas of alpine Rhaetoromance is conceived to be a supplement of the print version. It documents at least 21 investigation points (from totally 217), which are situated in the very core area of Ladin language in the Dolomite mountains (Val Badia | Abteital, Gherdëina | Grödnertal, Fascia | Fassatal, Fodom | Buchenstein, Anpezo | Cortina d'Ampezzo). The points are encircled on the following map by a dotted line the ("limite della Ladinia brissino-tirolese"):
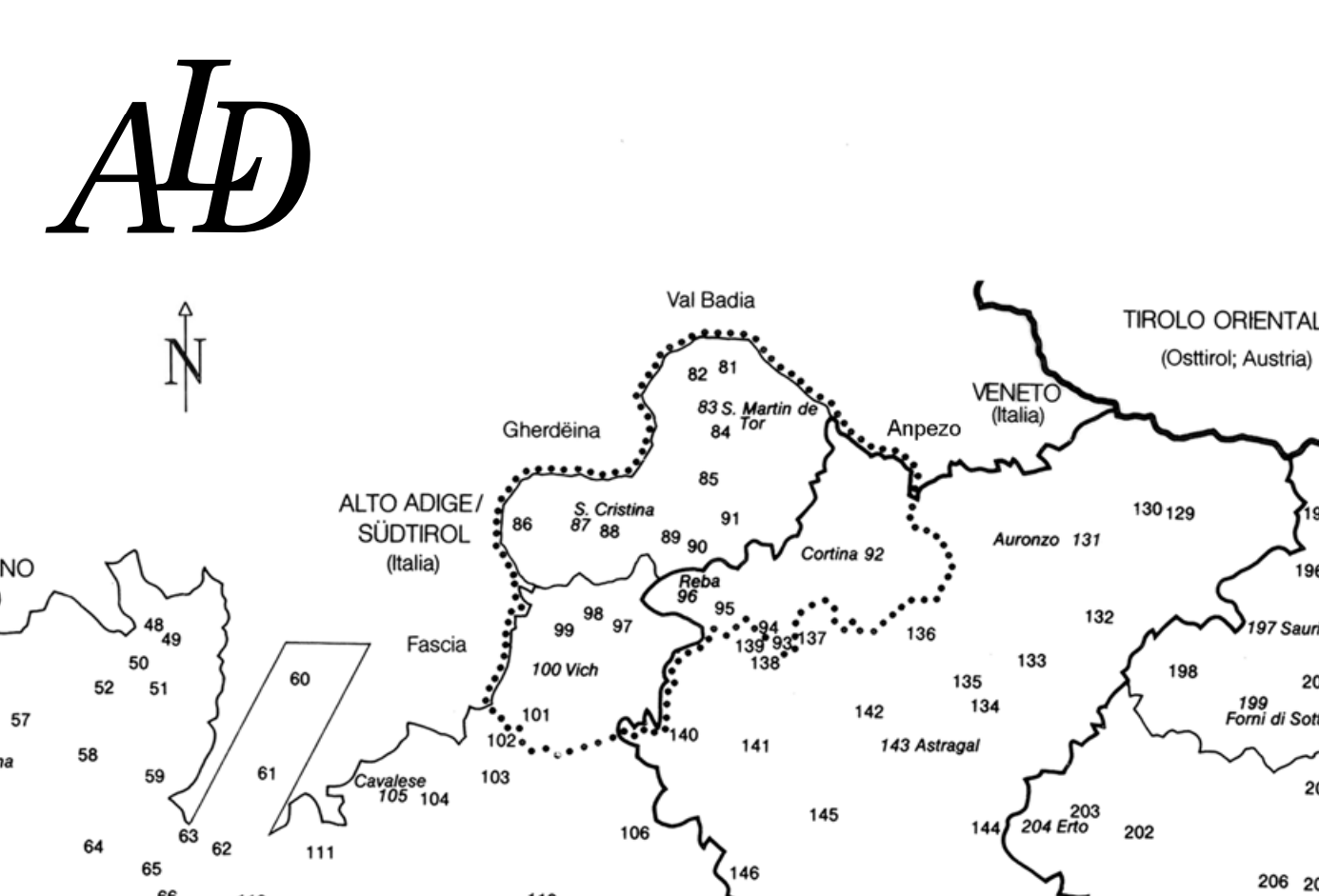
(4) Die 'Ladinia Brissino Tirolese' gemäß Netz des ALD
In three points of the Gherdëina valley (points 86, 87, 88) was noted the same phonetic type, l sak for ALD 678 il sacco 'the sack':

(5) der ALD Stimulus 'il sacco - i sacchi' im Grödnertal
In spite of the uniform transcription, the auditive impression is not the same, because in the points 86 (Bula) and 87 (Santa Cristina) the final consonant of the singular form is clearly aspirated, so that the transcription should be [-kh] - in contrary to p 88 (Sëlva), where the transcription [sak] is convincing. The question now is how the aspiration is to be interpreted. The two points are situated downwards, at the mouth of the valley and nearer to the language border. Two interpretations are possible:
- the dialects of the two villages 86 | 87 nearer to the Romance-German dialect border are stronger germanised, because the aspiration oft /K/ is without any doubt an influence of [kχ], characteristic of the German (Bavarian) dialects of South Tyrol; the feature would be a particularity of the local phoneme systems;
- the informants of the two points are bilinguals (like all inhabitants of the valley), but with German as their dominant language; in this case, the feature would be an effect of the individual speaker competence (and not of language system).
1.3. Example (2): Diatopic variation or speaker's level of education?
The following map (from Krefeld 2011) on the basis of 9 and 1536 shows by means of symbols (and not isoglosses) the use of pleonastic conjunctions in Northern Italy (quando che, cura che and mentre che instead of simple quando 'when', cura 'when', mentre 'whereas'). In points with readable numbers, only simple conjunctions were used.
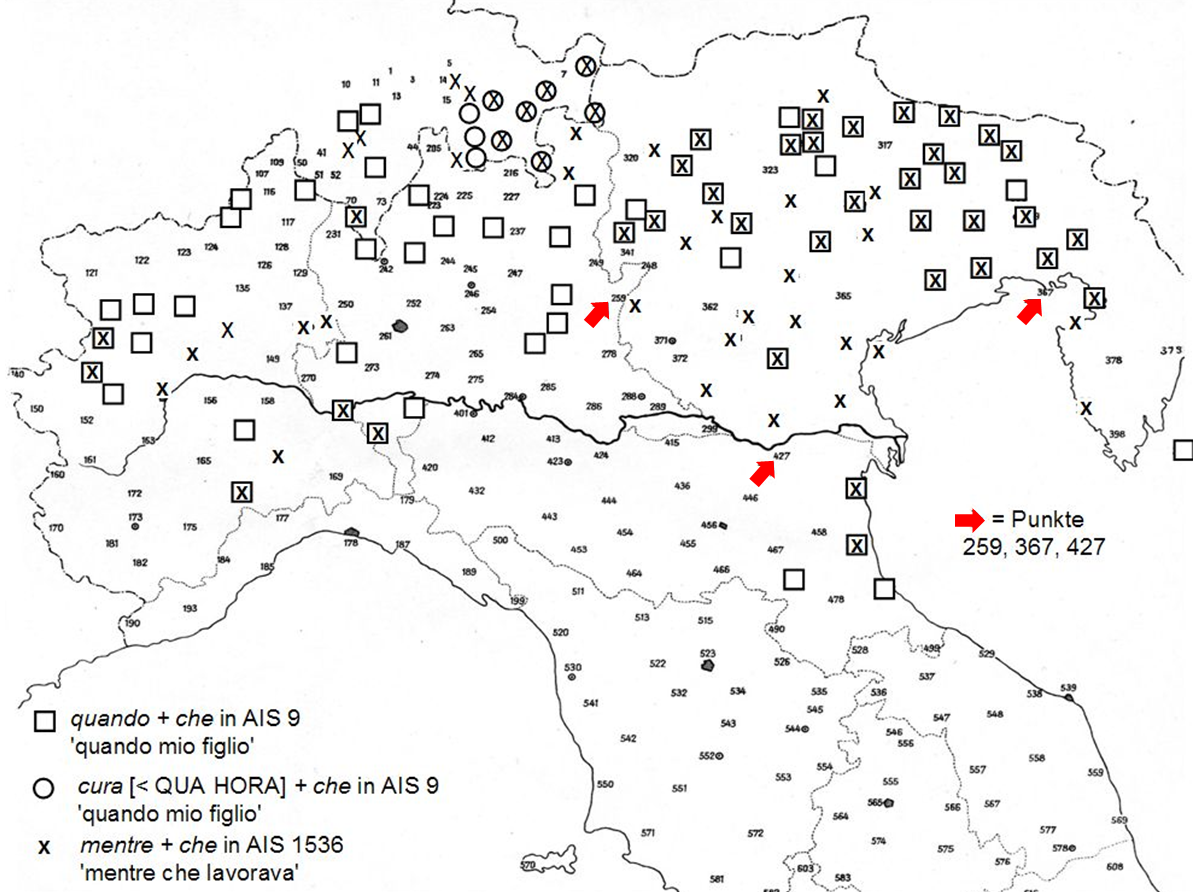
(6) Pleonastic conjunctions in two AIS maps (Northern Italy)
The question is now, whether the opposition between simple and pleonastic conjunctions is purely diatopic (or: dialectal). Nonwithstanding clear regional concentration, the global impression remains a bit diffuse. In three investigation points, marked with red arrows, the informants who use simple conjunctions were illiterate, as the proceedings tell us:
| proceedings | english translation (Th.K) |
| “259 […] Suj. […] geringe Schulbildung; Analphabet“ (Jaberg & Jud 1928, 69); | 'subject [...] low level of education. analphabet' |
| “367 […] Analphabet“ (Jaberg & Jud 1928, 88); | 'Analphabet' |
| “427 […] Analphabet. Schriftsprachlich beeinflussbar“ (Jaberg & Jud 1928, 94). | 'Analphabet. Influenceable by standard language' |
The variational status of these data is difficult to know: point 427 is at the edge of an area marked with 'x'; point 259 is situated in an diffuse area between 'x' and '⃞', and point 367 is completely isolated. There are two ways to handle this kind of records:
- The variant selected by the informant is assigned a marker on the level of language, 'diatopic' or 'diastratic' with respect to the informant's very low level of education. But note that the chosen simple conjunctions correspond perfectly to standard Italian.
- The speaker's variant selection is explained in the three cases by his linguistic insecurity; the cited notice in the proceedings of point 427 ("influenceable...") is a hint at this interpretation. The variation, however, is according to the speaker, and not according to the language system.
The story of the so called Dalmatian_language demonstrates the difficulty of dialectology in handling informants (see also Vegliotisch).
1.4. Multidimensional geolinguistics
After geolinguistics began to document different speaker categories and collected parallel data series which are visualised on the same map, the isogloss did not make sense anymore. The important innovation goes back to the two-dimensional atlas of the Middle Rhine region (Mittelrheinischer Sprachatlas [MRhSA]; see Bellmann 1986 and Bellmann 1994-2002), where younger mobile and older non-mobile speakers are confronted. This way, the MRhSA provided insights into the intricate relationship between dialectal and social variation.
Three further dimensions, age ('diagenerational'), level of instruction ('diastratic') and style ('diaphasic') were implemented and visualised in a completely new manner for the first time in the Atlas lingüistico diatópico y diastrático del Uruguay (ADDU) by Harald Thun and Adolfo Elizaincín (Thun 2000). The maps distinguish for each point four feature characteristics which come from four data series based on four informants:
Multidimensional visualisation on the base of four data series in ADDU
The same model was assumed by the Atlante sintattico della Calabria (AsiCa; see Krefeld 2017); but this online atlas introduced in addition interactive symbols that can be clicked in order to give dialect data or other informations.
A substantially new approach came from Sicily, where the Atlante linguistico della Sicilia (ALS) interviewed in its socio-variational part 15 informants in each point; data of three generations, two levels of education, two language systems and two competence types (L1= Sicilian and L1= regional Italian) were registered.
2. From geolinguistic to communicative space
The speaker's language use is no doubt conditioned by the above mentioned factors (age, education levels, sex) and, maybe, others more; although a total determination of language behavior does not exist. Every informant (as every speaker as well) does not only select variants within his repertory, he creates also new variants and by mere observation of spoken data it is not evident, whether a used variant is an occasional innovation or is conventional. Only the multiplication of the number of informants can tell us.
Consequently, the modelling of language variation and language dynamics has to be centred around the speaker and his repertoire. The speaker's position and the routines upon which he is building up his personal communicative space becomes the object of mapping. Obviously, this space is not geographical at all, but social. Roman Jakobson's classic model (see Jakobson 1960) allows to understand how this particular kind of social space emerges spontaneously and unavoidably only by communication. The reason is that the "factors" he mentions have an intrinsic relationship with space.
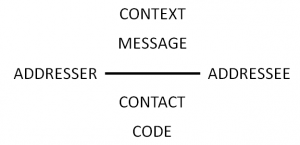
"factors, inalienably involved in verbal communication" (Jakobson 1960, 351)
Yet the most simple constellation, immediate speaking, is space bound because only possible, when addresser and addressee are sharing simultaneously, face to face, the same place. Face to face communication is furthermore embedded in everyday life's 'spatial scale' (see Schütz & Luckmann 1979-1984, 63-68)2; the zones of this scale are the personalised and near networks (N), the area of living and working (A) and the institutions of the state controlled territory (T). Now the efficiency of communicative space turns up, when we look how far the language/varieties of speaker's repertory and those of the scales match.
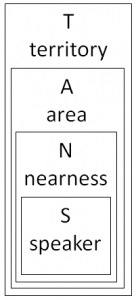
The speaker and three scales of communicative space
Note that the territorial language(s) (T) are in a way imposed by the state, top down, but as they are used in public education, and especially for alphabetisation they play an important role for cognition and for socialisation as well. Nevertheless, in dialect regions or wherever minority languages without T-status are spoken, the T-languages are not necessarily the dominant languages of N and A. The speaker-based modelling of communicative space allows to visualise how completely different individuals are living together in identical areas and territories:
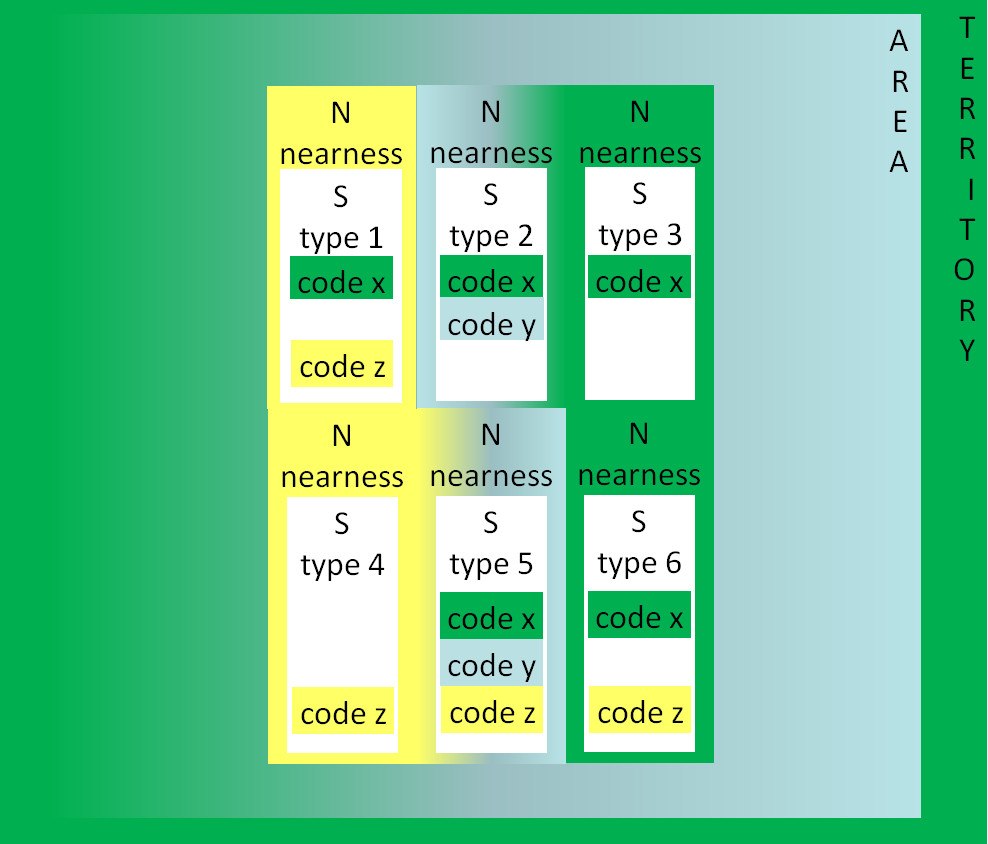
Speakers with different repertories sharing the same area and territory
| Some frequent speaker types (as above) | |
| (1) | bilingual migrant |
| (2) | dialect speaker |
| (3) | autocthonous without dialect |
| (4) | monolingual migrant |
| (5) | speaker with migrant ancestors |
| (6) | autocthonous with competence in migrant language |
The communication between speakers with different, only partially overlapping repertories is of special interest for the ermergence and the diffusion of linguistic variants, because it is the condition for spontaneous contact and exchange between different codes. The following figure schematises the communications between speakers having one code (CODE x) in common.
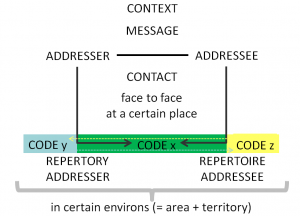
Communication between type 1 and type 2 speakers
The communicative behaviour of both is not only influenced by the purpose and understanding of the MESSAGE; because the specific verbal realisation of the MESSAGE is object of perception. The perceiving addressee is highly sensitive and filters out automatically all salient variants in phonology, lexic, morphosyntax and pragmatics; simultaneously connected associations are triggered. This is, in fact, the essence of markedness in variational linguistics (see above): it is nothing else but perceptual saliency of those variants which are associated with non-linguistic knowledge, e.g. 'who speaks like this has a low instruction level', ... 'has an Italian accent', ... 'comes from the countryside', ... 'is an urban teenager' etc.
To investigate the speaker's variation and knowledge is one of the tasks of perceptual linguistics (see the programmatic paper by Krefeld & Pustka 2010 and especially for diatopics the fundamental study of Christoph Purschke 2011). Much work is still to be done because the tradition of variational linguistics is exclusively concerned with production data. However, it is impossible to extract markedness only from analysing speech production (see Koch & Oesterreicher 1990).
Speech perception, though, is not only useful for resetting research in variational linguistics. It has a direct impact on speech production as well; when roles are inverted and the addresser takes the role of the addressee, he accommodates his speech often unconsciously to that he listened to immediately before (see Giles 2008) and especially for phonetics (Babel & McGuire & Walters & Nicholls 2014) nopar=true). Accommodation is a powerful motor of variant diffusion in the communicative space.
2.1. Basic units of communicative space - glossotopes
Geolinguistic concepts which are exclusivley speech-based are not compatible with an approach founded in the speaker's language repertoire and his routines using these languages in his specific linguistic environments. This basic unit might be called glossotope, from Greek γλῶσσα | glossa 'tongue, language' (TLG 353) and τόπος | topos 'place' (TLG 1806) (see Krefeld 2002, 159 and Krefeld 2004, 25). The founding idea of the approach is constructivist although the speaker is not presumed to be absolutely free: he can hardly elude the linguistic priming received by socialisation. But it is equally important to respect that his repertoire, apart from this original disposition, remains lifelong open-ended. The impact of other languages is unpredictable: his brothers and sisters may live with partners having another L1, and siblings as well with again other first languages and so on (see the case studies from Friulians in Bavaria analysed in Luca Melchior 2009). New WE-horizons may arise from these unpredictable networks, or: speaker communities, so that bilingualism and multilingualism have indeed a strong potential for identity (re)formation. The specific identity grounded in multilingualism has always been disregarded by dialectology and even in contemporary research about migration migrants are asked whether they feel to belong either to the region (and language community) they came from or to that they are actually living in. The existence of 'third' identities, experienced in a positive way, has to be accepted.
2.2. Glottoscopy 2.0: online-mapping of complex communicative spaces
Little is known about spatial structures behind communicative networks of different speaker types (as shown in ♦). We should therefore use the new communication technology in order to implement a kind of 'glottoscopy'3. Such a project must be driven by a continuous proliferation of informants and include the spatial relations created by mobile devices. The tremendous success of the smartphone is not least due to the fact that it allows different forms of quasi-synchronous communication without being present at the same place (see Jakob 2017).
Scientific use of web technology allows the following procedure:
- The data collection is done by smartphones or other mobile devices; data are georeferenced, with timestamp, and visualised on virtual maps.
- The informants are recruited and augmented by means of a structured but open network; dialect speakers with standard competence are also seen to be bilingual.
- When registering, each networker indicates his language repertoire, his sex and age.
- Only registered networkers invite others to whom they are connected by some social relation which reflect the scales of communicative space.
| scale of communicative space | social relation | languages/dialects |
| nearness | family/partner ♥, friends ♠, | ♥♥♥♥♥ | ♠♠♠♠♠ |
| area | clients/salespeolple/doctors/patients ⊕, unkowns without official function ⊗ | ⊕⊕⊕⊕⊕ | ⊗⊗⊗⊗⊗ |
| territory | representatives of national institutions (municipality, school) ♦ | ♦♦♦♦♦ |
- All networkers are asked at unpredictable moments in which language/dialect they are communicating at that very instant (or just before) and to whom. The moments of investigation are selected as to represent prototypical working hours and leisure time. The results might be visualised as in the following mockup pictures; the symbols stand for social relations (as above) and the colours for languages; the hyphen (-) marks face to face communication and the dotted line marks communication by media. The mockup example is willfully very small; the usability is realistic, because similar crowd sourcing technology is already used (for quite different purposes) in our project VerbaAlpina.
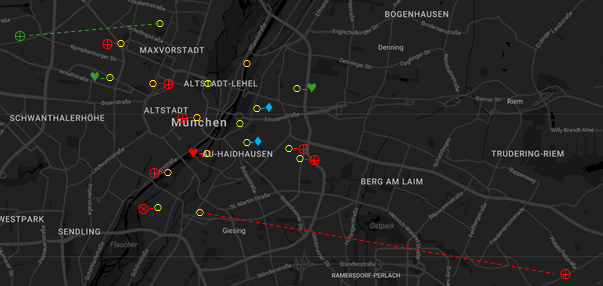
Mockup: the network's communicative activity at a moment of prototypical working hours (yellow circles = responding networkers)
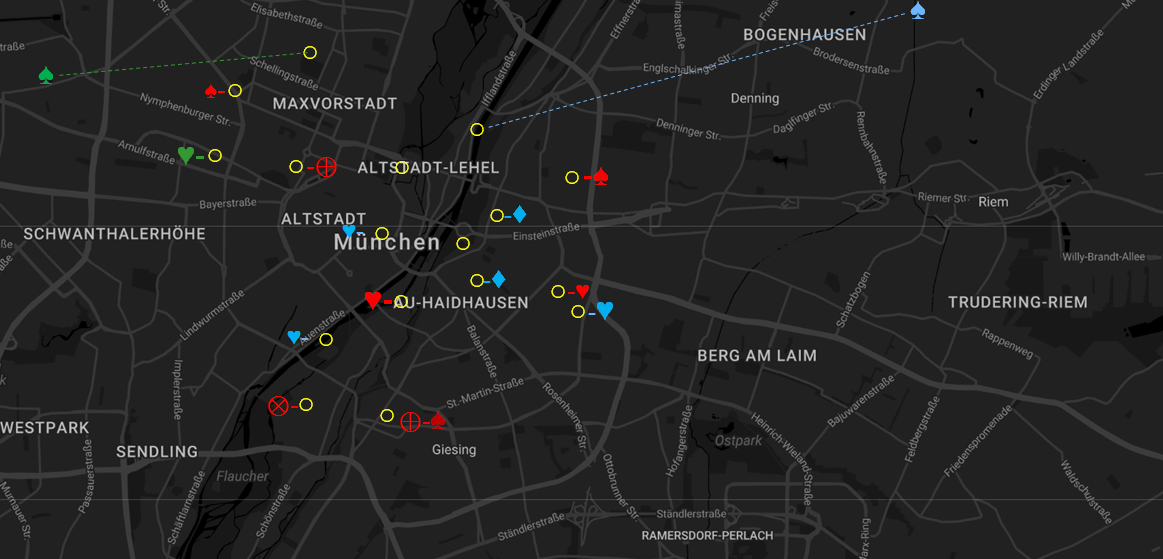
Mockup: the network's communicative activity at a moment of prototypical leisure time
All data could be filtered according to the different categories (social relationship, language etc.) or synthetically represented. This way the glossotopes of every networker will come out. Apart from mapping, statistical documentation or symbolic representation, as following, is imaginable.
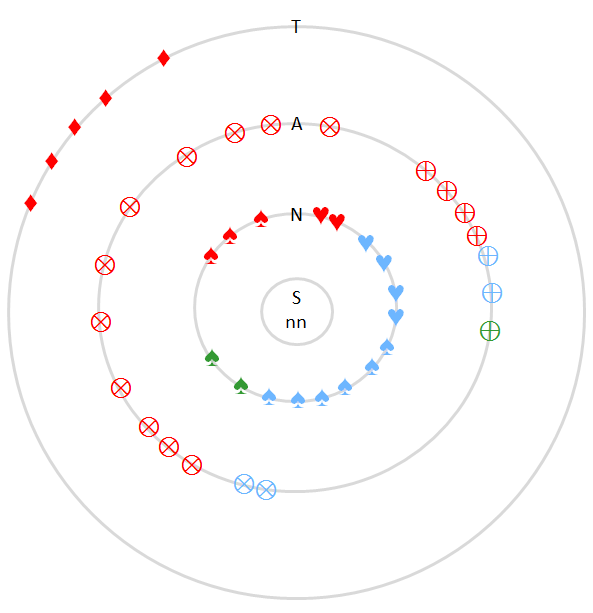
Hypothetic visualisation of a glossotope
The sketched method is also adapted for the representation of global family networks, which have derived in large numbers from 'classical' push areas of emigration. Families from Southern Italy, for instance, often have members living in two or three continents. To what extent new media and communication technology contributes to the maintenance of such intercontinental networks seems to be totally unexplored. It would be fascinating to document how identical input languages/dialects, e.g. Sicilian, grow apart to secondary migration varieties4 when exposed to different language contacts and embedded in different society types (e.g. Brasilian vs. German vs. Australian vs. Italian Sicilian):
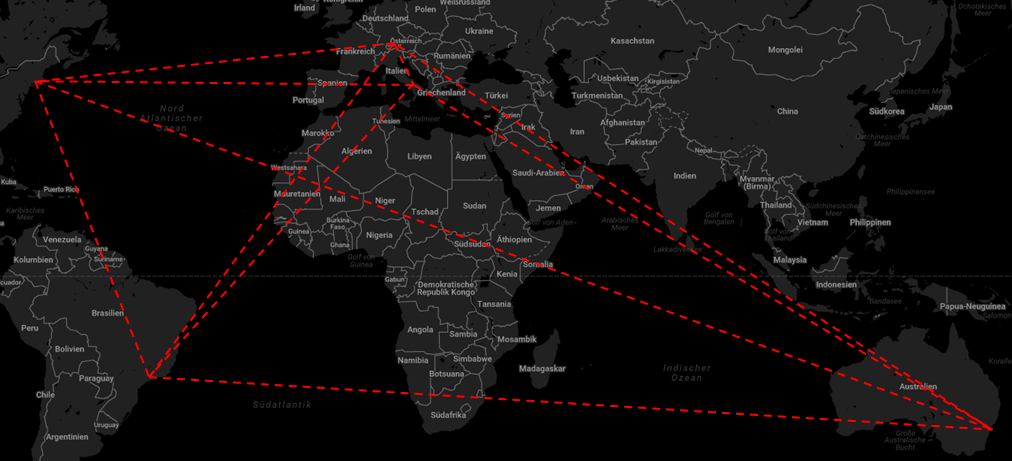
Mockup: migration induced communicative space (with Neapolitan nucleus)
Thus, the aggregation of connected glossotopes gives insights into the functioning of highly complex and dynamic communicative spaces. To put it in the way of the important German philosopher Gottfried Wilhelm Leibniz (1646-1716): Communicative space is what results from the individual glossotopes, when put together.5.